Foreword
我的blog基本就是我的知识库,都是一些比较冷门的知识点,我自己按照我的逻辑整理成的,之前就考虑过能不能结合我自己的知识库做一个AI,很久之前看过王登科的把自己的聊天记录做成了模仿自己说话语气内容的AI数字人,不过模仿语气我感觉不太需要,能正常提问回答出来我知识库的内容就够用了,语气什么的,客观就行了。
我也试过有道的、wolai的只能说在文档提问这一块还是有点挫,特别是wolai的基本是垃圾,不知道做这玩意干啥用,完全没有可用性。
iMa
https://iMa.qq.com/download/
最近听说腾讯的iMa知识库,试用一下,发现挺不错的,内容总结也可以,导入速度也挺快的,有原始的markdown文档就可以。
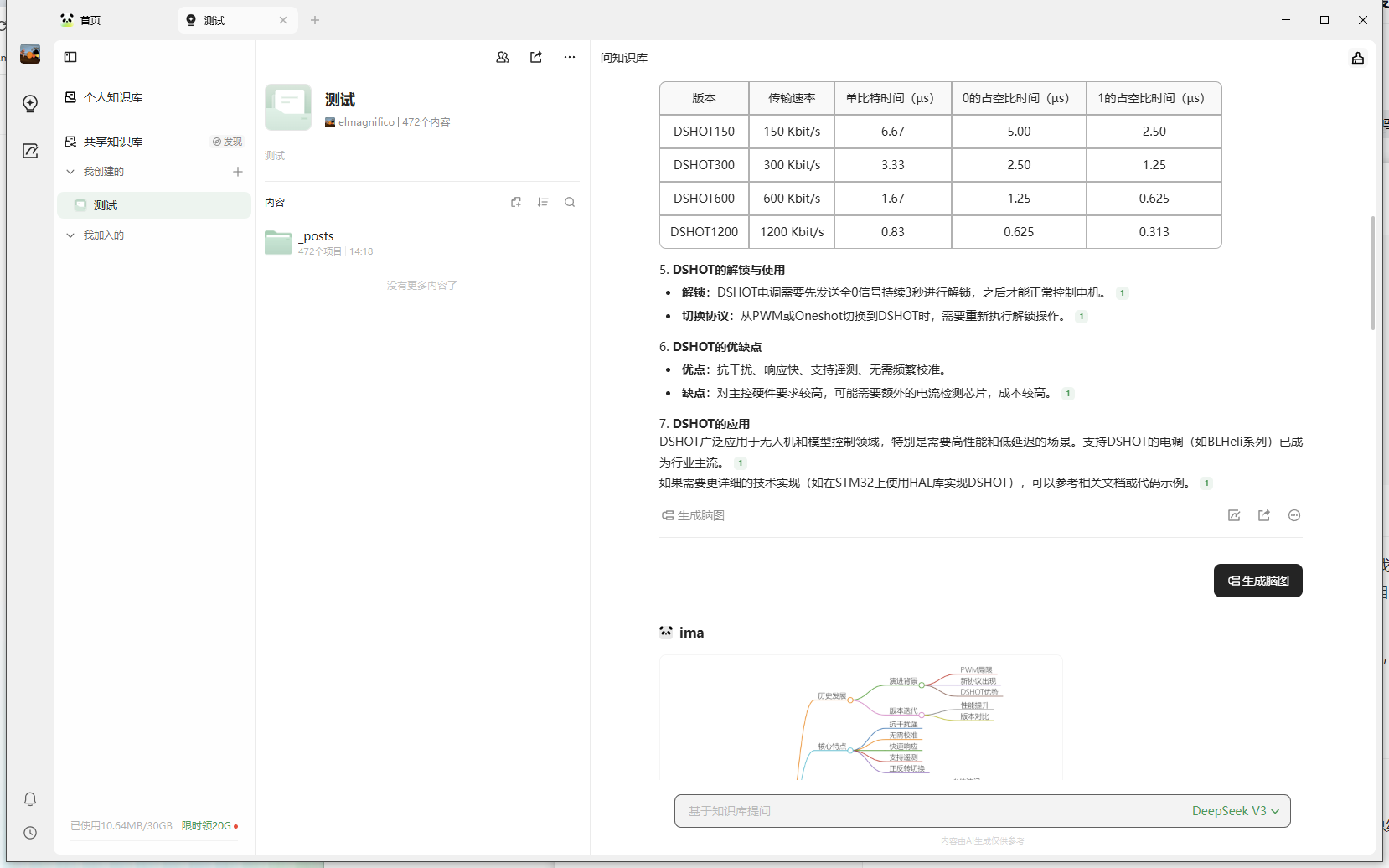
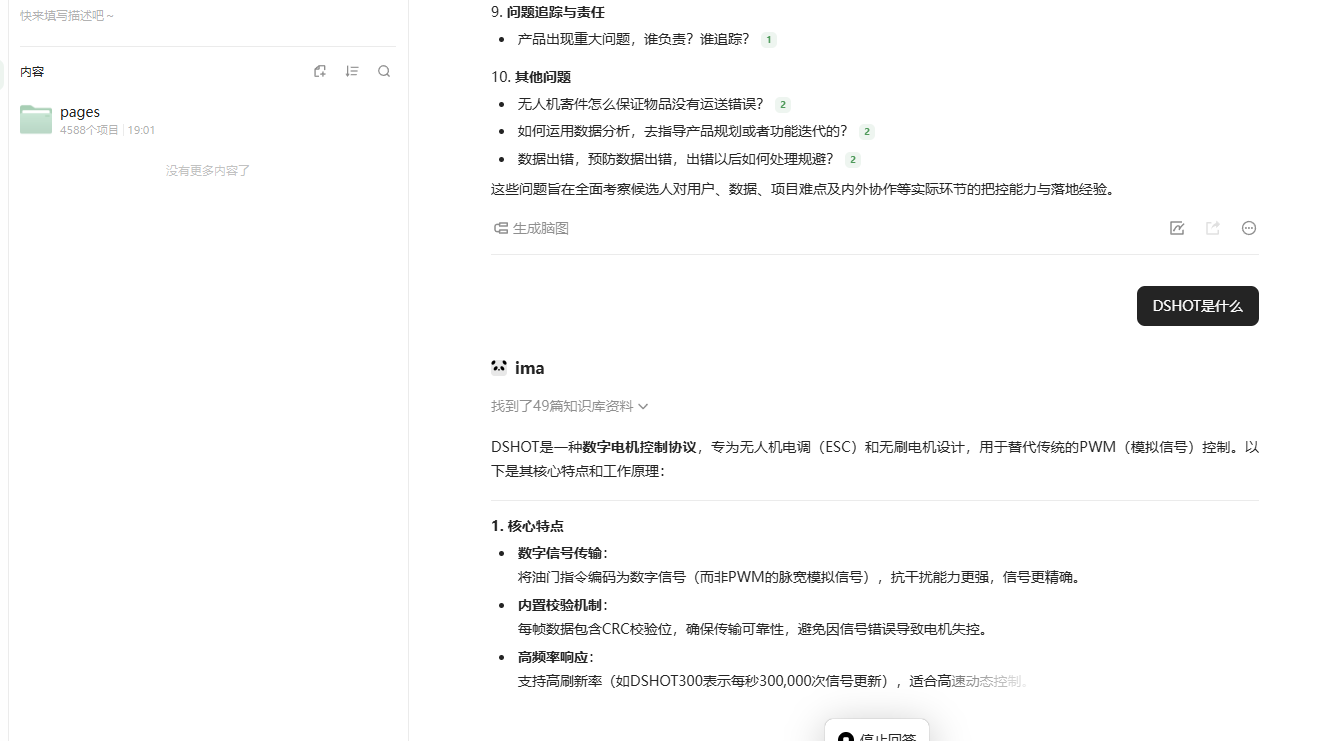
上手很简单,直接把我的blog的post全都丢给他,然后进行提问即可,速度很快,回答内容基本也是根据我文档来的?
目前支持常规的文档格式,好像支持剪藏?(需要浏览器插件),多端都可以使用
知识库建立好了以后,可以直接分享给其他人,也可以公开分享。
幻觉
如果提问知识库内没有的内容,他会从外部生成,iMa提到的42篇知识库资料完全和这个问题没关系
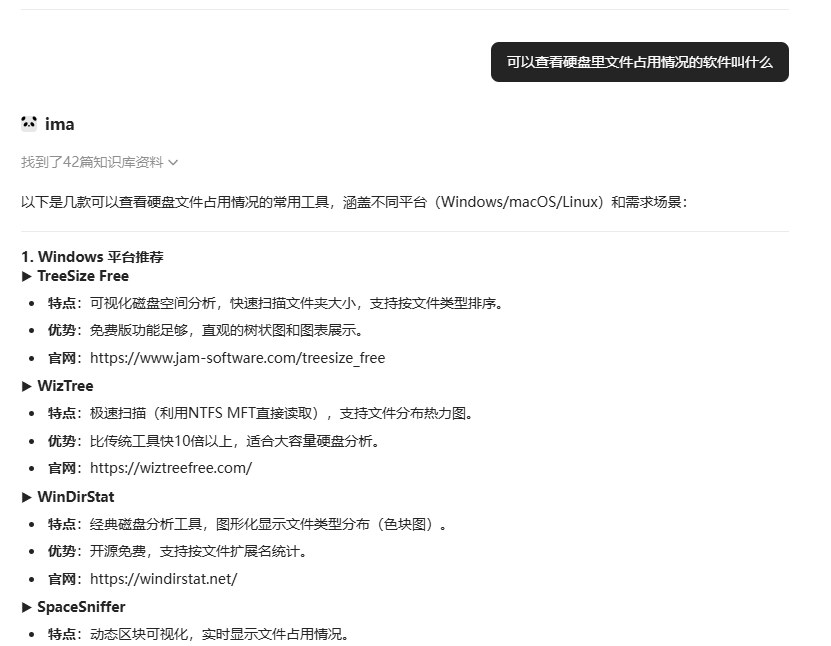
在我问到我写过的软件或者工具有哪些的时候,出现了幻觉,这个完全是胡说了,一共四行,四行内容都各说各话

读图能力
引入图片以后,也会有一个图片的概括,只是如果图片过多,整体解析速率就会降低非常多,图片的问题是他没有联系上下文,不知道这个图片所在位置关系,就缺少了很多关键性信息
但是,文档里如果包含这个图片,并且这个图片是相对路径的,那么iMa就不能解析了,他不知道这个图片路径在哪里,但是实际上我已经把图片传进去
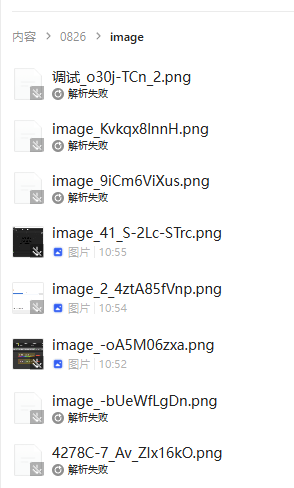
图片解析也存在部分图片无法解析,有的再次尝试以后可以正常概况了,有的完全不行
原理
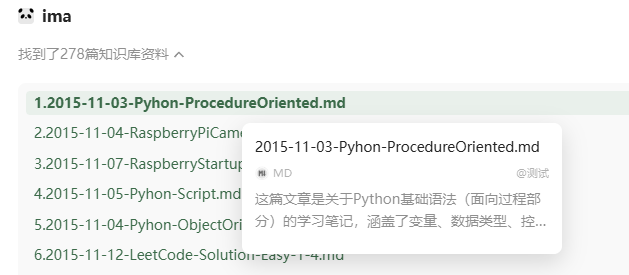
可以看到基本每篇内容在上传的时候都直接进行了一次AI总结,打了标签,总结以后作为一个搜索目录,再次问到相关内容,就从这个里面快速匹配
结合wolai
wolai的文档导出,是整个空间导出,需要一点时间,下载下来压缩包超级大,里面基本上是wolai的所有文件。
看了一下文件大概就有四五千个,总体md文件倒是没多大,一共也才15M左右,其他文件很多,图片、视频、各种数据文件等等。
wolai整体可以直接通过markdown的链接跳转,所有链接都是内部链接,用typora打卡之前wolai很卡的文档也非常轻松。
接着把这四千多个文件导入到iMa,做成知识库,大概花了将近40分钟才把文件全部转换完成。
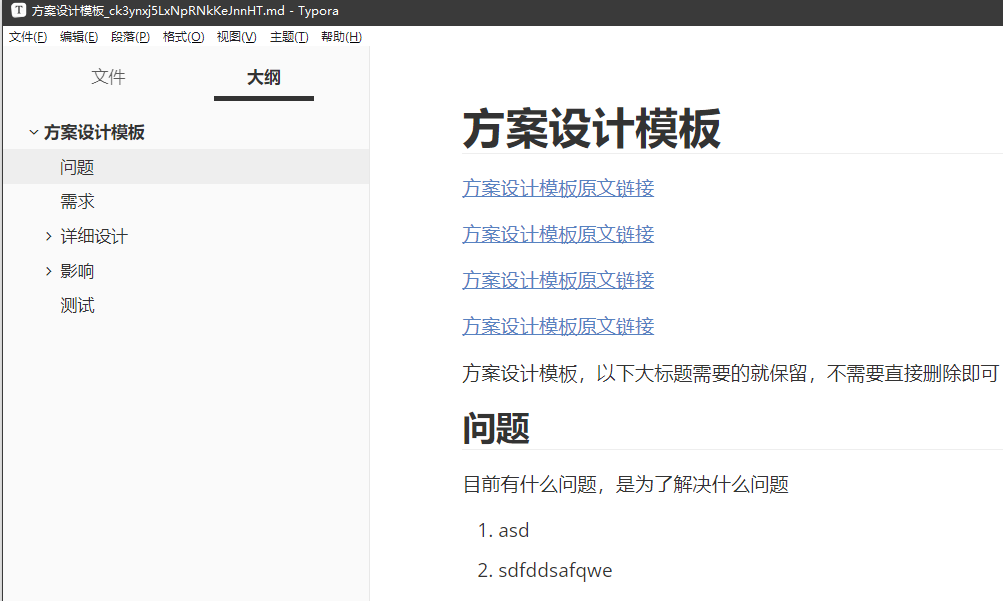
由于wolai文档本身没有按照空间划分,这就导致了所有文档是混在一起的,关联关系丢失了。空间划分也丢失了,同时也看出来了整个AI在做文件检索的时候,其实失去了文件结构的信息,比如文件下的子文件,这种都是有隶属关系的,但是大模型是不懂这部分内容的,iMa本身的提示词应该也没有处理这个的能力。这样就导致了提问的东西如果涉及到很多个文档的内容,会出现内容拼接,把新老内容拼接在一起,那么得到的答案就有点离谱了
需要注意一下,由于wolai直接导出,内容十分多,也有很多敏感信息,这部分内容需要单独剔除,还是挺麻烦的,特别是各种账号密码记录的哪里都有,每个文档都需要单独删除
其次也发现了一个新问题,文档怎么更新?
iMa本身好像没有更新这个概念,那我重新导出一次新的wolai,就要重新走一遍前面的文档导入流程,改几个字都得这样,这也太麻烦了。iMa可能本意是把用户或者知识库留在他本身,可能没想到外部更新的情况
结合wolai,由于wolai的每个文档都有对应wolai的后缀,那么就可以利用这个后缀加个批处理程序,把原生wolai的链接给写回原文,这样需要找对应wolai文档的时候就可以直接跳转访问,很简单
import os
# user for replace pic fomart str in markdown doc head
# first get all file
dir = r"K:\Download\LCXkl4\pages"
origin_str = "Forward"
replace_str = "Foreword"
line_num_limit = 30
delete_file_list = [
"81SN8ME8AdNA16WrmgFLfL",
"wKojQFStFZDQ5JXDkULrUn",
]
for file in os.listdir(dir):
# show file name
print(file)
# 检查文件后缀是否为.md
if not file.endswith('.md'):
continue
# 获取文件名中下划线到点之间的内容
parts = file.split('_')
if len(parts) > 1:
# 如果有下划线,取最后一部分并去掉.md后缀
name = parts[-1].split('.')[0]
doc_name = parts[0]
#print(f"提取的内容: {name}")
# 如果文件名在删除列表中则跳过
if name in delete_file_list:
print(f"删除文件: {name}")
os.remove(dir + "\\" + file)
continue
url = "https://www.wolai.com/你的用户名/"+name
#print(url)
insert_str = "["+doc_name+"原文链接]("+url+")"
#print(insert_str)
file_path = dir + "\\" + file
f = open(file_path, encoding='utf-8')
content = f.readlines()
f.close()
# 在第二行插入链接
new_file = ""
for i, line in enumerate(content):
if i == 1: # 在第二行插入
new_file += insert_str + "\n\n" # 添加两个换行确保格式正确
new_file += line
# 写回文件
f = open(file_path, 'w', encoding='utf-8')
f.write(new_file)
f.close()
这样就可以在访问内容的时候快速跳转到原文
如果只是服务于搜索,那只需要添加wolai的pages就行了,但是如果还要内容,还需要把image也同时加进去,否则所有图片链接都是无效的,只不过加了图片以后文件数量就好几万了,大小也一下来到了3g多,上传速度就比较慢了
Summary
实际回答效果咋样和具体用啥模型还是有关系的,只是iMa帮你把这部分内容给你结合起来了,做好了文档梳理。
总体分享还是非常便捷的,但是文档笔记本身书写体验还是比较挫的,本质上是markdown的一个变体。
iMa文档内容可以逐步增加,可以给不同人权限,作为新人初期了解一下新公司,制度,新行业的内容,还是挺方便的,直接提问就行了。
但是这个东西只能作为内部的搜索的一个环节,大家交流的文档本质上还是要基于更细化的管理,协同,内容审阅,这个部分iMa过于缺了,实际用起来可能也是你想到了用一下iMa提问,没想起来那就找人问了,iMa的存在感略微有一点低。
还有一种就是iMa放出来对外的接口,作为一个小服务,类似F1,问号,Office的大眼睛那种存在的方式进行,iMa相当于是其后端管理,或许还有一些额外的发展。
Quote
https://iMa.qq.com/