Foreword
GPU相关一些基础建设的常识
GPU CPU NPU TPU
TPU,张量处理单元,主要是进行矩阵乘法计算
NPU,其实类似TPU,但是他是一种定制的计算规则,比如矩阵先乘后加,先加后乘,或者是更复杂的乘加乘加等等,相当于是定制化的计算单元,他是有适用的局限性的。如果专门为某个算法而生,那么这个算法就能吃满硬件加速,远超CPU或者TPU等其他方式实现的计算速率。
GPU,主攻并行计算,常常需要CPU指挥,广义上GPU是包含了TPU、NPU的,所以主力是强大的专业算力。
CPU,主攻逻辑运算,广义上CPU是可能会包含NPU和TPU,GPU的,但是多而不精,遇到一些专业问题,还是得专业的来搞。
但是,其实现在GPU的广义定义可能又发生改变了,英伟达新系列已经把一个小CPU作为协处理器融入到了GPU芯片中,这样GPU里就会包含CPU,因为在AI计算力,CPU不是大哥了,对于CPU的需求不是那么高,那么直接融一个ARM系列的GPU进去,显然是十分容易的。而且本身英伟达以前就做过客户端的ARM系列的CPU,这算是老树开新花了。
算力局限
问一个模型,如果可以给无尽的资源,那么这个模型的训练、运行效率会被什么东西卡住。
目前来说,主要被限制的大概就是三个地方,GPU算力TOPS,GPU显存大小GB,GPU显存速率(如果显存无限大,可能没这个事情)。
粗浅的可以把模型分为训练和推理两个阶段:
- 训练阶段,主要吃GPU算力,显存大小
- 推理阶段,主要吃显存大小、显存速率
训练相对推理来说,是更需要资源的,基本什么东西都要更好,更高的
推理阶段,往往是为了高并发,服务大规模使用者,而需要更大规模的GPU集群,但是模型本身可能只需要单GPU就能运行了。
NvLink、NvSwitch、NvLink Switch

NvLink,早年的NvLink主要是可以让双卡之间直接进行通信(NVLink Bridge),可以共享显存,而不需要走PCIe通道,让别人帮忙转发消息,这样速度非常快
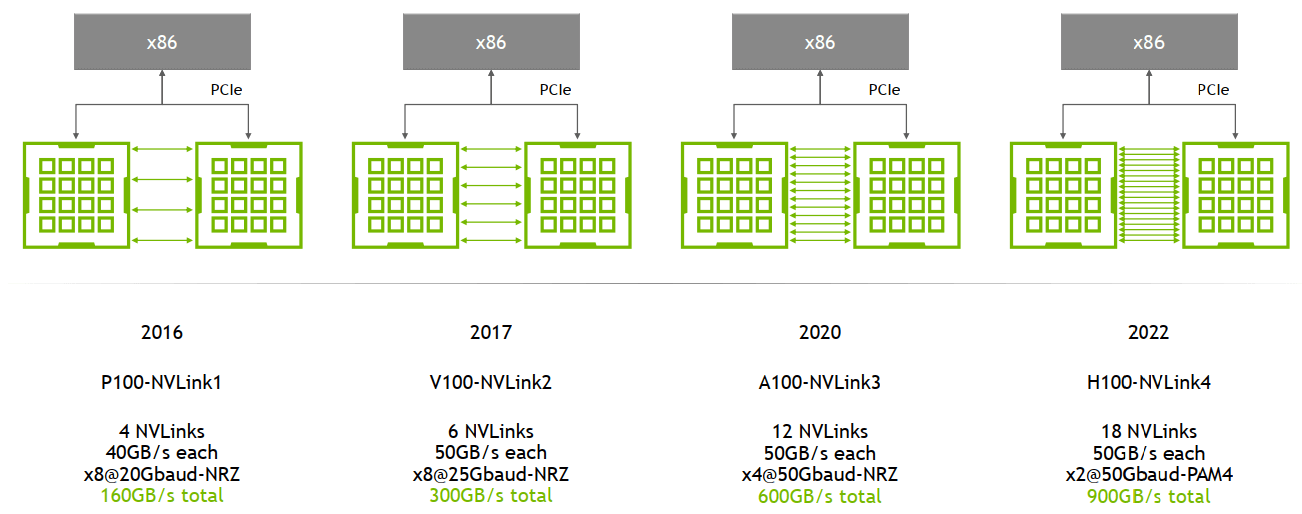
这样速度可以达到双向900GB/s,远超内存等速率,但是此时NvLink只能双卡,双卡的规模面对巨型AI来说,还是太小了,于是乎就有了后续NvSwitch。
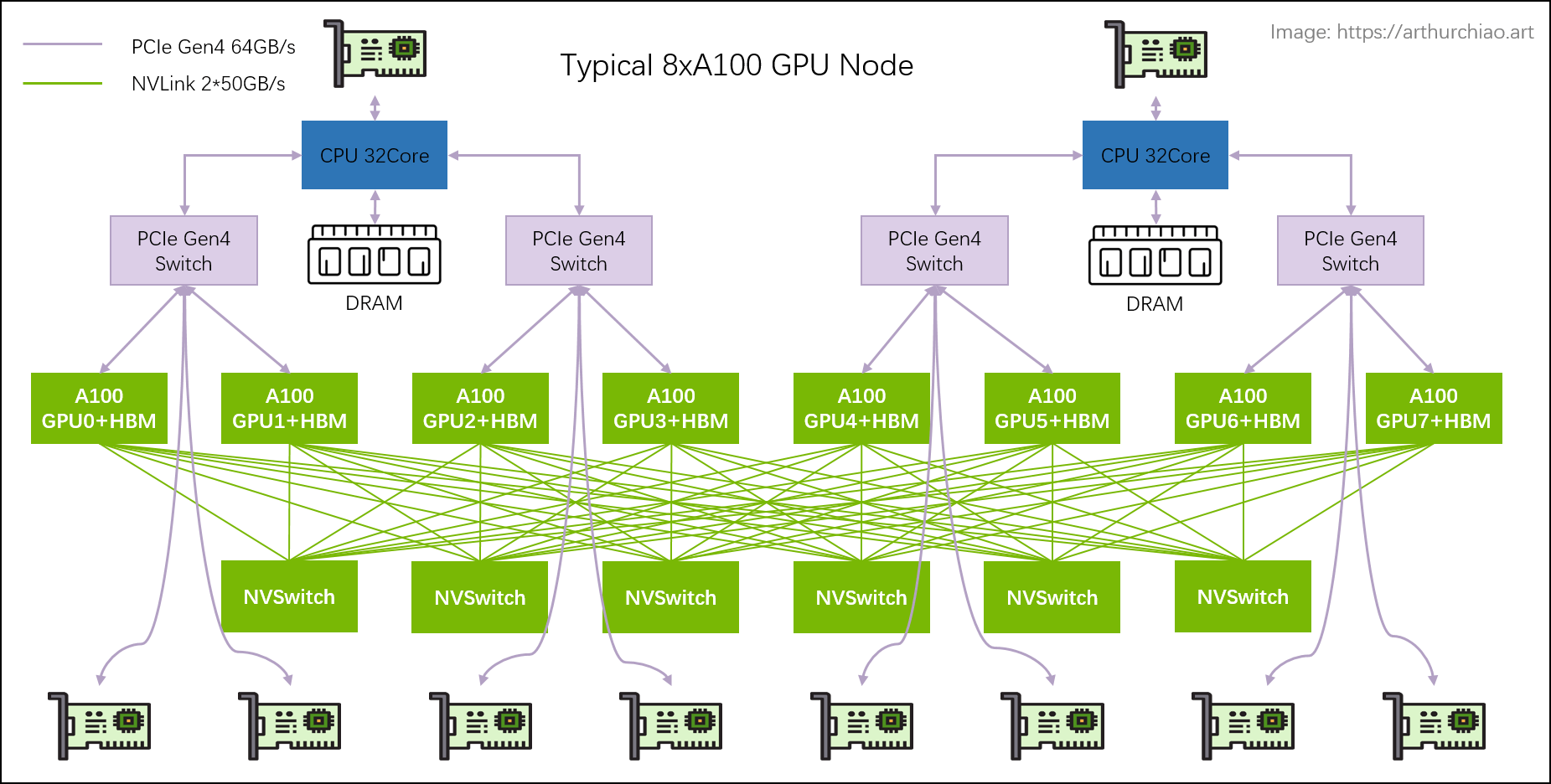
NvSwitch,就让原来的NvLink从双卡拓展到了8卡,8卡之间可以互相通信共享显存了。NvSwitch可以认为类似网络中的交换机,但是它实际上一个芯片模块,是直接在GPU主板上的。到了这个阶段,还是无法满足超级大显存的需求,于是乎又有了NvLink Switch。
NvLink Switch,他是真的变成了GPU的交换机,他变成了一个独立设备,用来跨主机连接不同的GPU集群。
除了NvLink这种英伟达自家的集群方案,还有一种就是通过网络来组集群,只是这种方式速度要比英伟达的方案慢一些
PCIe,HBM,DDR,NvLink,Ethernet
主要是说明数据链路级别的瓶颈
PCIe,目前最新是6.0,但是还没有实物,5.0才刚落地,速率大概是32GT/s,就算是6.0也才64GT/s,单通道是大概是7.876 GB/s,如果使用更多通道就可以*n,比如16通道就能达到126GB/s,单向速率也就是63GB/s。
DDR,目前最新是6.0,还是没实物,5.0落地一段时间了,速率大概是12800MT/s,明显比PCIe慢了许多
HBM,目前最新是3.0,速率大概是819 GB/s,比PCIe和DDR都要快很多,但是3.0还没落地,现在还是2E
阶段,速率大概是461GB/s,所以目前是GPU的首选内存
NvLink,起步就900GB/s了,甚至比HBM还快
Ethernet,目前落地的200Gb/s的网卡,只能达到25Gb/s的传输速率,整体比PCIe还是要慢一些的。
所以如果组集群或者涉及到多个GPU服务器之间通信,最后的瓶颈往往都落在了这个网络和GPU到PCIe的头上
算力架构、CUDA、ZLUDA
抄个表格,这里只说了英伟达和华为,其实还有AMD和一些其他厂商,只是规模比起来有点小而已
| NVIDIA | HUAWEI | 功能 |
|---|---|---|
| GPU | NPU/GPU | 通用并行处理器 |
| NVLINK | HCCS | GPU 卡间高速互连技术 |
| InfiniBand | HCCN | RDMA 产品/工具 |
nvidia-smi |
npu-smi |
GPU 命令行工具 |
| CUDA | CANN | GPU 编程库 |
| DCGM | DCMI | GPU 底层编程库/接口,例如采集监控信息 |

比较关键的就是CANN/CUDA,他整体定义了整个GPU算力的计算逻辑,或者说你能发挥多少GPU算力,都取决于这里怎么实现。
不同的模型或者算法,底层计算逻辑可能是不一样的,需要结合硬件对算法进行优化、加速,那么英伟达就提出来了一种基于英伟达GPU的通用接口,只要你按照这个逻辑去调用GPU,就能完整发挥这个GPU的硬件性能,否则每次算法或者模型都需要对不同的GPU做适配,这不得累死。
CUDA就成了英伟达的护城河之一,CUDA在整个领域中占比可能有90%之多,之前AMD搞得兼容CUDA的兼容层,都是为了想办法抢一部分他的客户,你不兼容CUDA,那你就要重新写底层优化,那就不具备通用性,那谁愿意用呢。
NVIDIA GH200
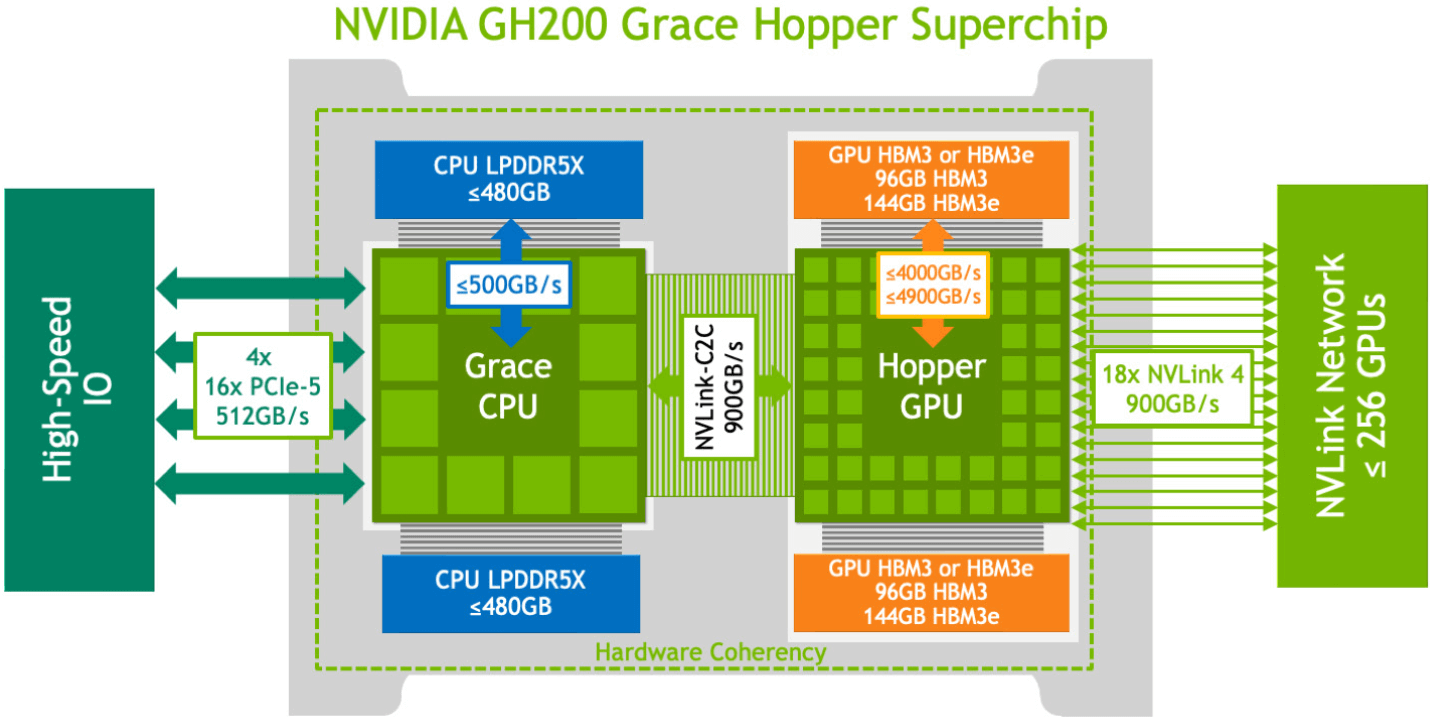
到GH200 这里,英伟达就意识到了之前服务器的局限,这里直接用自己的CPU和GPU,然后把内存也内置进去,然后这些内部访问都是可以直接通过NvLink的,不走什么PCIE了,相当于抛弃了传统服务器那一套东西,我自己玩了,充分降低了整个系统间互相通信的延迟。
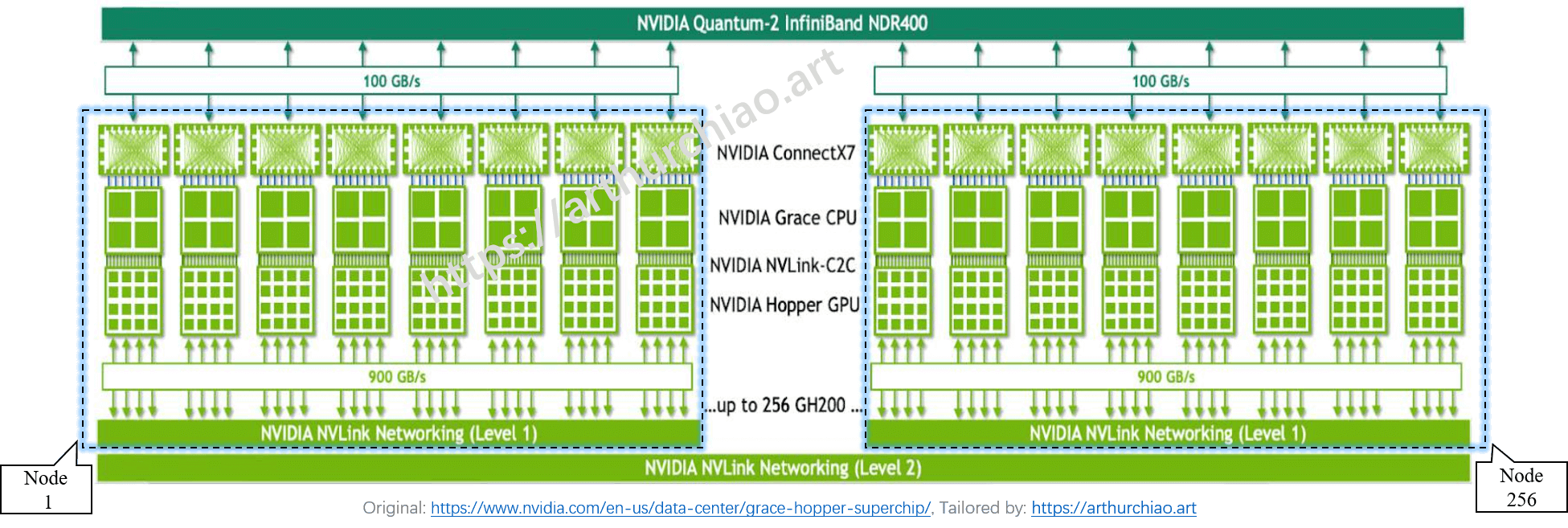
基于GH200 构建了一个机柜NVL32,他直接就能提供19.5TB的内存+显存,而且任意一个GPU都可以访问,而且还能再扩展显存。这个机柜还能再次组成集群,从而适用于超大规模的模型的训练和推理
Summary
后续有新发现再补充
Quote
arthurchiao.art写的很详尽,拿来入门很适合,作者应该是携程的赵亚楠,看他的blog里基础和翻译文比较多,下面几篇基础都写的挺好的,值得一看
https://arthurchiao.art/blog/gpu-advanced-notes-1-zh/
https://arthurchiao.art/blog/gpu-advanced-notes-2-zh/
https://arthurchiao.art/blog/gpu-advanced-notes-3-zh/
https://arthurchiao.art/blog/gpu-advanced-notes-4-zh/
https://developer.nvidia.com/zh-cn/blog/nvidia-nvlink-and-nvidia-nvswitch-supercharge-large-language-model-inference/
https://www.nvidia.cn/data-center/nvlink/
https://www.bilibili.com/video/BV1SZdwYTEM8