Foreword
最近类ChatGPT非常火爆,但是百度也要跟着凑热闹,但是我并不看好,谈一谈我自己的观点
对比
文心一言
文心一言是16号发布的,我十七号拿到了测试资格
https://yiyan.baidu.com/
简单的解释一下人工势场,测试结果只能说十分离谱了。
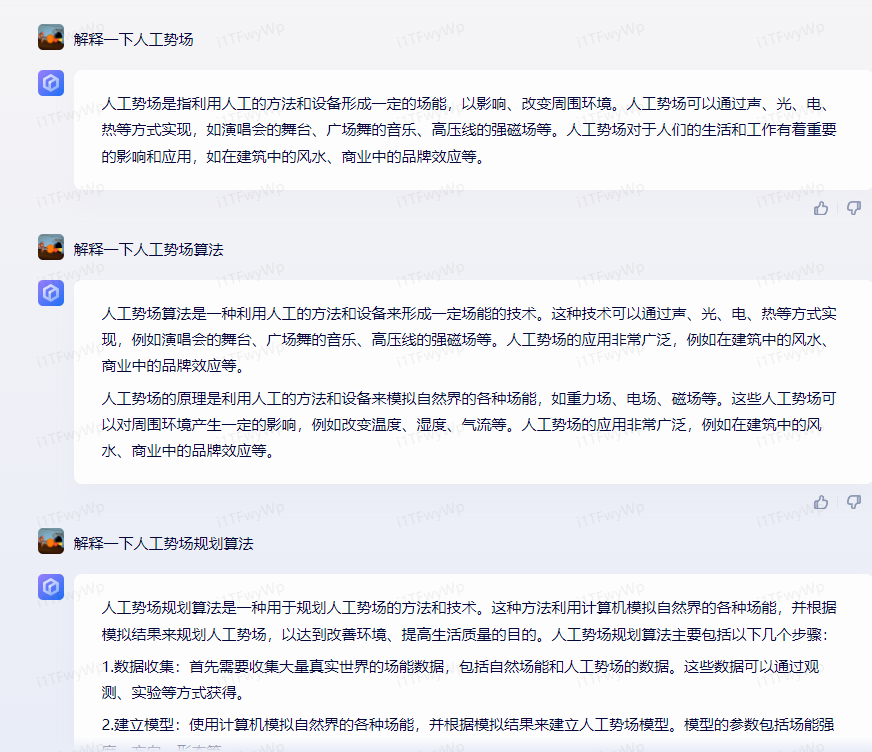
不是很清楚百度的数据源到底是什么,但是很明显百度这个实在是差太远了,基本等于胡扯。
自然语言的理解也很明显,比ChatGPT差远了
通义千问
通义千问,过了一个月才给测试资格,还是用企业身份申请的
https://tongyi.aliyun.com/chat
ChatGPT是阿里的,你tm咋好意思的,看到以前别人的测评还不会这么说的,现在直接就改了是吧

建议文心一言和通义千问先打一架

还好世界不是中国的

通义千问,明显比文心一言要强很多,回答速度也快很多,感觉非常流畅,唯一的问题是AI会被灌输不正确的内容
ChatGPT初级阶段
以目前来说,ChatGPT对自然语音的理解已经非常不错了。但是这个东西真正投入使用,不仅仅是对语言的理解,目前阶段我们只是对ChatGPT进行输入,而貌似我们得到的输出只是语言文字、图片之类东西。但是如果要商用,那么ChatGPT就需要输出分解后的用户的实际需求,然后再对接到第三方进行实现,这个东西才是真正可以商用的内容
这就好比你需要咨询xx,于是找到了一个行业资深的从业者(AI),描述了你的需求,于是他给出了一通分析、给出了一些可能的推荐,最终你从这些推荐中选择了一个你满意的,并进行尝试。
目前ChatGPT提供的API还只是自然语言的理解和回答,商业需要的是能输出对应的指令,就比如简单的智能家居命令
目前的语音助手:
小爱同学,请开灯
小爱同学,请关灯,打开空调,保持26度
自然语言
好黑,看不见了
别浪费电了,关灯吧,好热啊,开个空调吧
自然语言肯定不会说的这么标准,那么就希望ChatGPT可以理解并且将其转换成对应的API指令,传递给第三方,实现最终的效果
灯,打开
灯,关闭
空调,打开
空调,温度,26
当然现在直接教ChatGPT,告诉他按照某些规则进行输出,做角色扮演是可以的,只是目前实现肯定还是不够优雅,能满足的情况并不够好。
实际上各种图片或者视频之类的处理,本质上就是我上面说的将用户的输入转换成了API指令,然后调用了其他模型,返回结果后再转给用户。
至于使用ChatGPT写代码,那就大可不必了,简单的代码确实能写,不过这种程度的我还需要你吗?Code Pilot不香嘛
目前我能想到的应用场景大部分都和搜索和顾问、咨询、客服一类的东西相关,以前可能需要人去理解的东西,大部分情况可以让AI去理解或者说让AI做80%的普通问题,剩下20%交给专业的人。
我估计下一阶段ChatGPT会开放更加商业化的API,可以轻易的将指令传输到第三方。

搜索与担忧
如果有一天ChatGPT代替了搜索,那么担忧就来了。首先ChatGPT的内容是训练的,那么他的数据库里有什么就非常关键了,不想你搜到的,那你就绝对找不到。甚至ChatGPT自己就可以做过滤,直接将一些内容彻底屏蔽。
如果只是屏蔽,倒是罢了。可怕的是他在无形之中将推广、营销、各种广告概念也融入其中,那么最终出现的这个到底是个什么东西?现在来看百度水平不够,还没走到那一步,技术不会做恶,但是人会,终有一天他会拿这个来牟利,那时你得到的又是什么?
现在搜索好歹还有一个小小的广告标签,当那一天到来的时候,还会有吗?
ChatGPT目前不仅仅是搬运文字而已,他是带有一定的推理和理解能力的,从目前来说这里还有非常大的漏洞,可以被用来做很多灰色、黑色的事情。同样的,ChatGPT的进化过程中,如何能让他不过分推理理解,不在原本的内容上胡说八道,这我觉得更重要。如果我想要的仅仅是一个ChatGPT作为知识库的助手,那么就更不能让他过分理解和二次解释。
ChatGPT的本质
https://www.bilibili.com/video/BV1Tc411L7UA
看OpenAI的首席科学家和老黄的对话,确实说了一些关键性的东西,之前有些我也不太理解的东西,看了视频和评论大概理解了
伊利亚(Ilya),视频中的OpenAI首席科学家,最早在12年的时候,首次使用GPU(AMD580)加速CNN计算,在当年的图像识别比赛中拿到大奖,也是自此开启了GPU和AI的联系,之前大家都是matlab、c++等等利用CPU进行计算的,但是当时能研究的问题都比较小,计算量上不去,神经网络能得到的效果也非常有限。从此以后,大家开始使用GPU加速计算,GPU在此时也从原本的图像领域开始分叉,向着AI和CNN计算开始进化,随着算力一步步提高,CNN带来了一个又一个AI相关的突破,但是这依然不够。
Ilya团队看到了CNN和GPU能带来的效果,他们想更进一步,走向更大、更深的CNN,于是有了OpenAI,有了ChatGPT这种非常庞大的数据模型,这种深和大,给CNN带来了质变。AI不再是像个傻逼一样,只会回答一些定式,而是非常像人类一样,会推理,能理解自然语言等等。这个质变是大家都明显看得出来的。
一些比较有用的评论
伊利亚(openAI的首席科学家)的这个直觉太关键了,对数据的高度压缩本身就是无监督学习的有效实现,推理及其符号不是现象背后的本质,而是一种组合的可能路径
你所记忆的就是你所学的 ai不需要学习只需要记忆
大规模的,同态的,合理分布的数据集就是对于世界模型的良好一阶映射,深度神经网络则可以对这些数据包含的信息进一步压缩,抽象,学到数据背后的知识(即高阶概率组合),并以序列预测的形式将推理过程展现出来,预测准确度越高,则推理越符合世界模型
人话就是生成模型可以看成是训练数据的压缩。。因为模型比数据小很多,却拟合了训练数据的分布
当我们收集到大量的医疗数据,这些数据包含病人的各种信息,如年龄、性别、体重、血压、心率等等。这些数据可以被视为对于世界的一个良好的一阶映射,因为这些数据反映了真实世界中的医疗情况。
接下来,我们可以使用深度神经网络来进一步处理这些数据,并学习到这些数据背后的知识,例如某些症状与特定疾病的关联等等。然后,我们可以使用这些知识来预测未来的医疗情况,例如预测某位病人是否可能患上某种疾病,以及他们可能需要哪些治疗方法。
如果我们的预测准确度越高,那么我们的推理就越符合真实世界的医疗情况。因此,我们可以使用这种方法来提高我们对医疗领域的理解,并提高治疗和诊断的准确性
假设我们有一张 1000x1000 的彩色图像,其中包含了很多细节和颜色。但是如果我们想要用这张图像来训练机器学习算法,那么我们并不需要保存每一个像素点的值,因为这些值中可能有很多是冗余的,或者没有对我们要分类的物体有影响的。因此,我们可以对图像进行压缩,以提取出最有用的特征。比如可以使用主成分分析 (PCA) 算法,将原始像素点压缩成更少的特征向量。这些特征向量可以表示图像中的主要形状和颜色分布,提供给机器学习算法使用。
而将数据转化为组合的可能路径,可以通过使用卷积神经网络 (CNN) 来实现。CNN 可以将图像中的每一个像素点看作是一个节点,然后将它们组成一个类似于“路径”的结构,这个结构可以表示出图像中的物体形状、边缘、颜色等信息。这种表示方法可以帮助机器学习算法更好地理解图像中的内容,从而对分类、识别等任务提供更有力的工具。
关键的两个问题 先无监督压缩世界,学习世界的表征,再进行微调,完成具体任务。新时代的两阶段学习。 第一阶段由企业完成, 第二阶段个性化
目前自监督已经解决了,通常比较清楚了 第二阶段就是他们的秘密了还不是太清楚如何使用强化学习,进行微调适应个性化
神经网络的推理 当我们训练一个大型神经网络来准确预测互联网上许多不同文本中的下一个词时,我们正在做的是让机器学习一个经过人类压缩提炼后的世界模型,也是世界本质的一个映射。神经网络预测的下一个词越准确,那么它对世界本质的还原度就越高,对世界的分辨率也就越高。 为什么预测下一个词越准确会能有真正的理解。就像给你一篇很长很复杂线索还很隐蔽的侦探小说,在小说的最后一页侦探召集所有人说他会公布谁是凶手,这时候如果能准确预测出凶手,那么就对整篇小的世界有深刻的认识。
一些我的思考,现在的AI还只能从文字上学习这个世界的知识,或者说获取这个世界的模型,但是文字还不够。所以Ilya表示GPT4已经开始从音频、图像、视频方面开始学习这个世界。从Ilya的角度来看,他是把AI当作人的,或者说类比做人,来推导AI的发展。
从我的理解来说,文字让人类可以继承知识,从而可以站在巨人的肩膀上继续前行。AI仅仅学习文字的知识其实是不够的,或者说片面的。文字能记录的也只是一部分,而人类的世界远比文字复杂多了,很多东西是文字描述不了的。人是视觉动物,回想人的成长,在还看不懂文字、说不出话的时候,是从视觉和听觉来感受世界的。Ilya后续的思路也是一样的,想要继续让这个模型扩大、更深入,就必须给他更多的知识,所以要从视觉出发,(听觉其实转化成了文字),给AI另一个维度,让他继续去理解这个世界。
目前来说AI获取的信息量还是远不及人类,AI虽然可以获取全世界的知识库,但是他目前还无法借此直接生成逻辑链,没办法像人类一样简单的提取很多很明显的特征,而人类可以。
将来的某一天,AI可以获取到整个世界的映射,那个时候他可能真的成为一个数字生命。
一些概念
Transformer,这个词经常被提及,大多数人说的太复杂了,我简单解释一下,想让计算机能计算我们的语言,那么必须给我们的语言一个数学模型或者数学上的定义,让他变得可以被计算,这就是transformer主要解决的问题。而平常的文字,如果只是单独编码,他们都还是离散的,无法衡量,两句话含义的相似程度或者向左程度,为了让两句话可以被衡量,Transformer对这里的词和字重新进行了编码,进而让他们组成的句子什么的可以被计算,最后可以吐出来预测的下一个词或者句子。
RNN,循环神经网络,RNN因为其循环连接的特殊结构可以方便的处理序列数据,而文本、语音、视频等数据从人类的角度看,在时间上具有连续性,是时序数据,适合使用RNN
CNN,卷积神经网络,多用于图像计算,CNN网络可以看成人类视觉机制的一种初级模仿
压缩,压缩某种程度上说是各种神经网络的核心,将原本庞大的知识或者信息,压缩到可计算或者说可利用的程度,其实就是对万千世界的一种极致抽象,相对人来说,他已经很努力了,但是依然还是初期阶段,对人来说一眼就能分辨的东西,对机器来说需要超大量计算才能提取到其中的特征,而这个特征还不是任何公式或者变量就能简单描述得了的。

监督学习,简单说就是用一部分已经标定好的数据去训练,因为已知结果,所以可以直接反馈给AI是好还是不好,最后去解决未标定的数据问题,可以说是以偏概全、管中窥豹
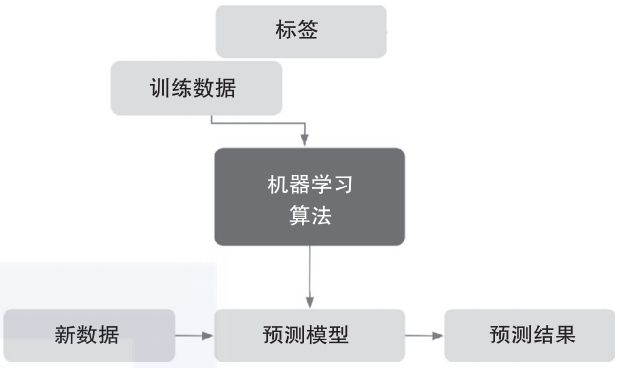
强化学习,和监督的不同在于,对于问题本身,我们也不知道当前的结果是不是好或者坏,或者说精确的值,我们只知道相对好或者相对坏,那么为了让AI能够运转下去,就对他得到相对好的结果进行奖励,当作一个反馈,进而让他自然进化,最终达到可以解决未知问题的程度。最大的不同点就是反馈
无监督学习,由于连人也不知道数据中到底有什么,所以给不了任何反馈,也不能标定数据,一般都是各种聚类算法对数据归类,从而找到数据中的特征,进而形成未知的标签。然后可能会有人为干预,去观察这些未知的标签到底是什么,把未知标签变成已知标签,把未知数据变成标定好的数据。他的核心是打标签
Summary
让时间走起来
Quote
http://www.taodudu.cc/news/show-4811339.html
http://pg.jrj.com.cn/acc/Res/CN_RES/INDUS/2023/2/14/5be2a09e-5ab3-41af-940d-0fdc97240d38.pdf
https://hub.baai.ac.cn/view/24531
https://zhuanlan.zhihu.com/p/613378443
https://orangeblog.notion.site/GPT-4-AGI-8fc50010291d47efb92cbbd668c8c893
https://www.bilibili.com/video/BV1Tc411L7UA
https://zhuanlan.zhihu.com/p/125139937
https://www.jianshu.com/p/e0afd5d348de
https://www.zhihu.com/question/34681168