Foreword
上次使用可能还是在小时候了,当时还玩过CheatEngine的小游戏。不过当年各种游戏对内存反hook的保护基本没有,想咋弄就咋弄。使用技巧还停留在简单的找数值,这次稍微提升了一下,也搞明白了一些基础内容。
自动搜索基址
还记得以前找个基址是真的麻烦,必须得一点点反向找,一个地址找一天,现在可好,直接暴搜,机器性能强了,也确实效率高太多了。
看了2个视频大概就明白是咋回事了
https://www.bilibili.com/video/BV1Cf4y1p7bX?share_source=copy_web
https://www.bilibili.com/video/BV1c4411R794?share_source=copy_web
相当简单,第一步找到了数值以后,Pointer scan for this address
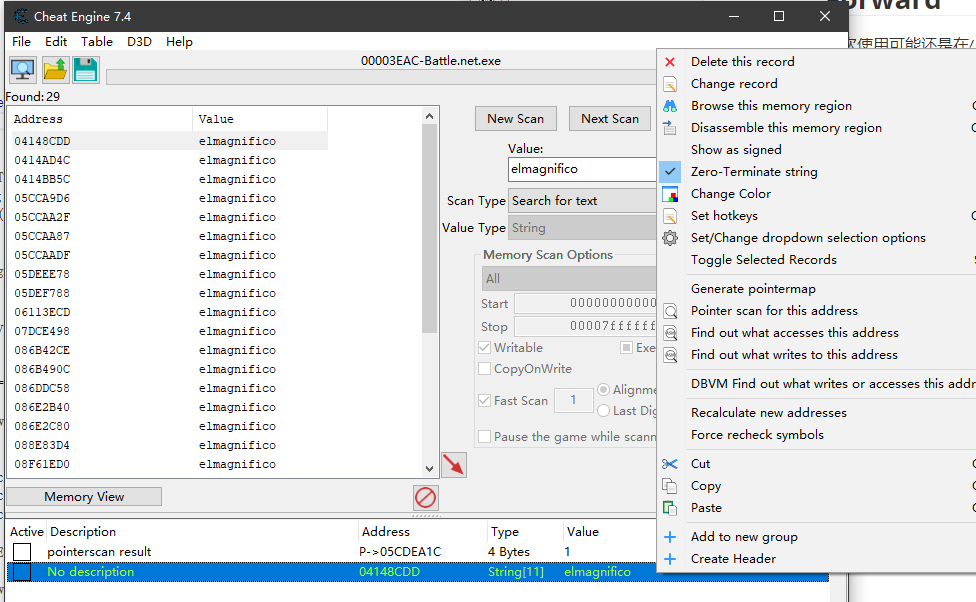
然后主要就是调整搜索的深度,越深花费的时间就越多,并且搜索到的条目也会越多。
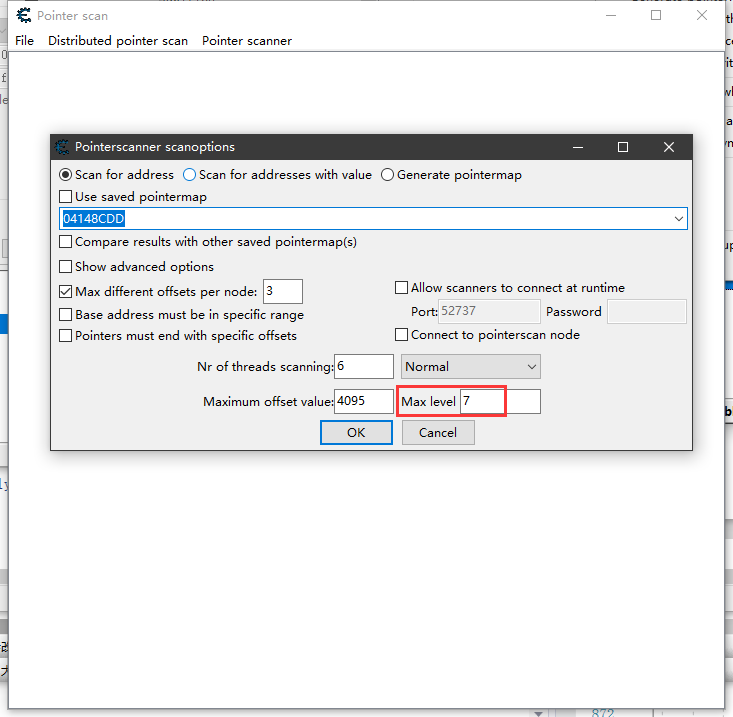
一般第一次建议直接从3层开始,搜完以后,不关搜索结果的情况下,重启目标客户端,然后看一遍结果是否有正确的。如果有那就算找到了(这种级别基本没啥保护了)。如果没有就继续加深搜索,再验证。
需要注意,这里会提示保存位置,最好每次都用一个新文件,我发现当搜索结果少的情况下,他覆盖不全,会导致上次的搜索结果融入到本次,有点难受。而且每建一个新文件,想返回上次结果也能重新加载。
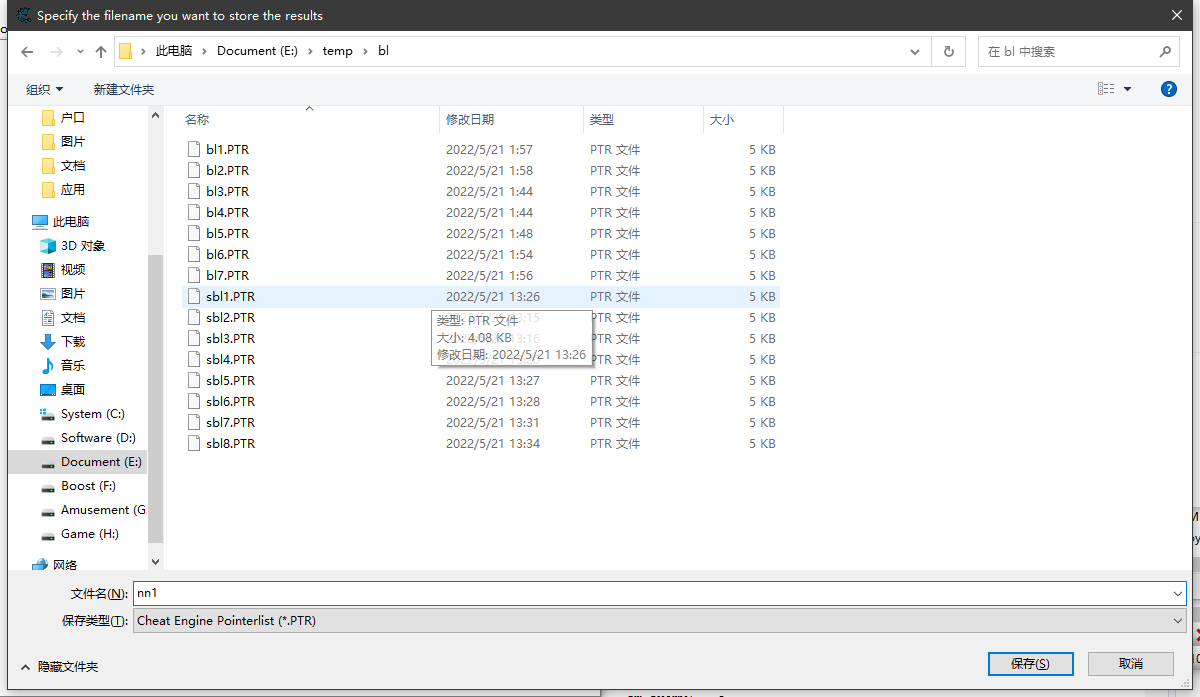
- 搜索结果是每条一个独立文件,存储位置可能文件数量会爆炸。
结果过滤
每次的搜索结果,首先通过右键Resync modulelist来刷新一遍所有的结果
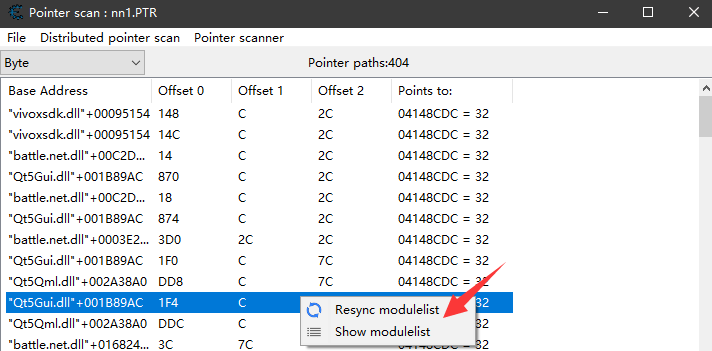
然后如果结果太多了,建议通过Rescan memory来从当前结果中再过滤一次
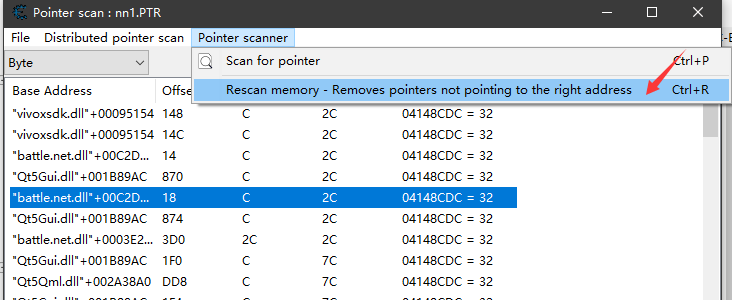
结果过滤一般可以通过2种方式,一个是依然指向当前地址的方式过滤,一个是值过滤。
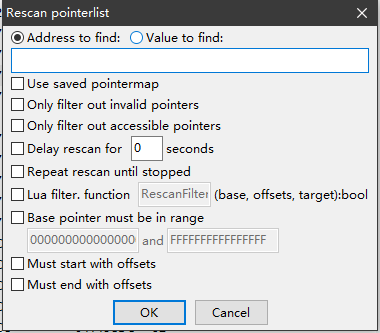
当前地址过滤这个一般不行,因为你重启客户端以后,目标地址一般都变了,所以用值过滤比较多一些。主要是通过值过滤,来找和之前相同值的基址。
这里也有需要注意的点,搜索显示的结果转成的值,和二次筛选用的数据类型可能是不一样的,最好弄到一致。
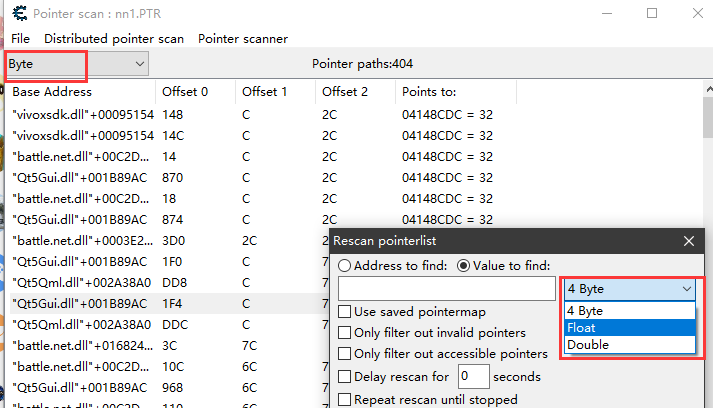
否则会出现2个值对不上,永远找不到可行基址。
- Rescan 的速度相当慢,注意左下角的搜索提示,经常以为搜索完了,其实并没有
有了以上技巧以后,找基址就变得非常公式化,也非常简单了。
模式识别
而现实情况是,游戏可能为了保护或者更新或者什么,经常会出现基址改变的情况,这种情况要怎么办呢?
我从MapAssist里学到了他的模式识别。简单的理解,一个变量的地址不太会无缘无故的单独移动。每个变量在内存中的排布,一般而言都是整齐且规律的,并且程序每次的编译顺序,大部分情况下也是固定的。所以一个变量如果移动,那么势必他周边的变量也一定会跟着移动,基于这样的情况,就可以设想,其实地址附近会有一些其他变量可能具有某些特征,只要找到了这个特征就等于找到了这个地址。
- 这个地址不是基址,直接就是目标数值的地址
示例
比如这里我的目标地址是05CDEA1C,可以看到他附近,有一些字符串可读。
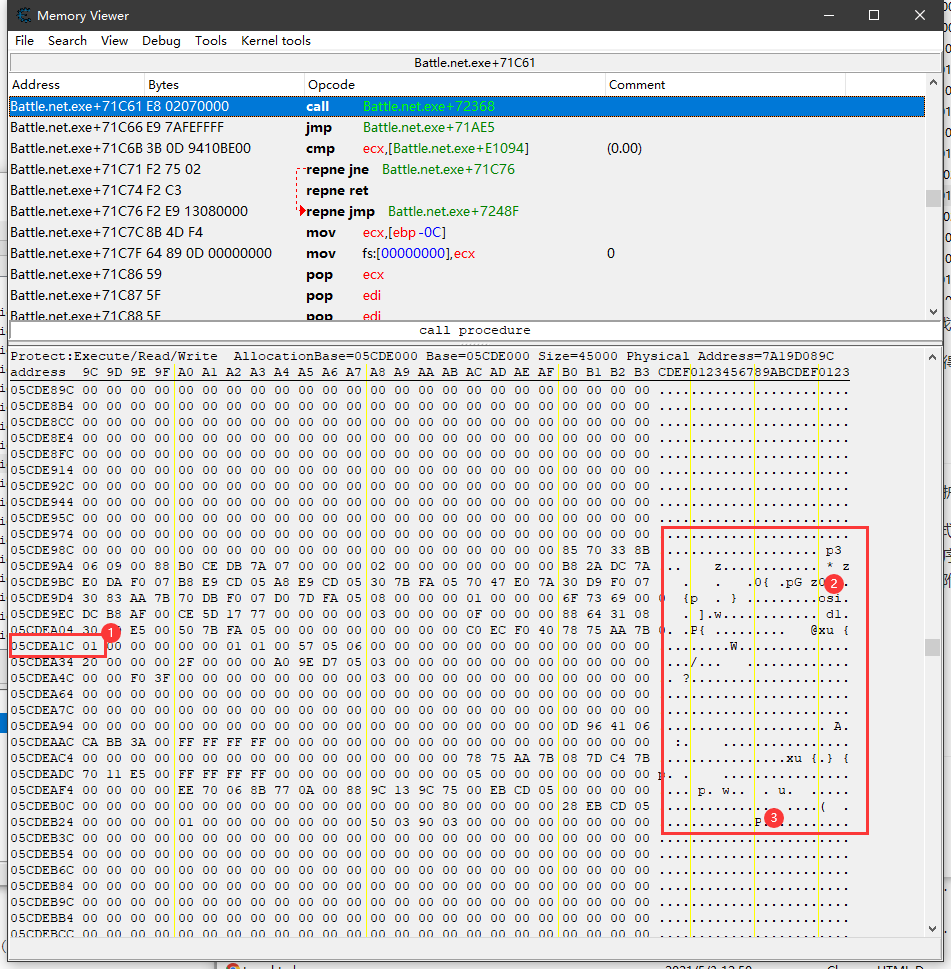
通过多次重启测试,发现每次2-3都有部分值是一样的。
那么只要根据这个一样部分的数值,去内存里暴搜,就可以轻易得到这个数值地址了?当然这需要先验证一下。
直接通过CE搜索数组,然后将相似的 尽可能长的一串数值带进去搜索,一般情况下能找到的结果都只有几个。这就很好用了,多的结果可以通过简单的排除判断就能被丢弃了。
这样的好处就是,以后就算游戏更新了,只要不动这里相关的变量,那么这个位置的特征基本就是稳定的,不需要跟随游戏一直更新基址。
特征码,其实这里应该找的就是基址特征码,而不是随便一个固定字符串。基址的特征码是基于这段代码的调用结构生成的,比如在进入这个位置之前执行的一系列操作,这些操作码,只要源码没有改动,那么就是固定的,可能他的操作数是一些变量,所以将其替换成??通配符即可。
这样就可以非常简单的组合出来一个特征码,除此以外,还需要确保这个特征码最好能在整块区域里唯一,从而可以方便的找到这个位置。
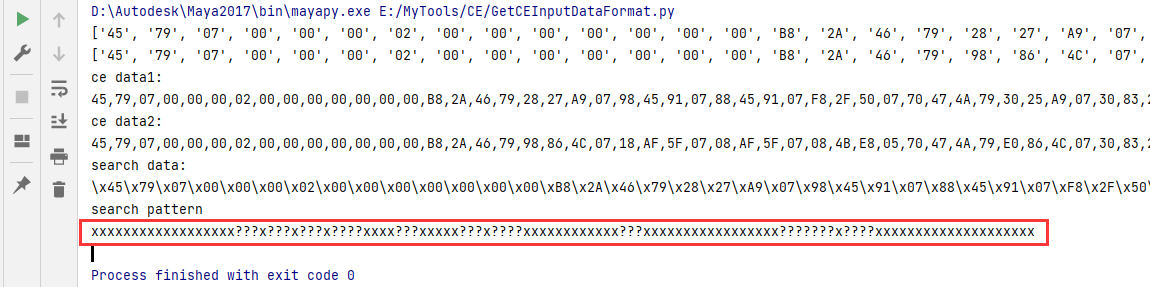
模式识别代码
为了简单快速的看出来是否两块地址附近内容的相似性,写了个小程序,输出模式结果
https://github.com/elmagnificogi/MyTools/tree/master/CE
f1 = open("./data1.txt")
f2 = open("./data2.txt")
data1 = f1.readlines()[0].split(" ")
data2 = f2.readlines()[0].split(" ")
f1.close()
f2.close()
len = min(len(data1),len(data2))
print (data1)
print (data2)
ce_data_format = ""
for i in range(len):
ce_data_format+=data1[i]
if i < len-2:
ce_data_format+=','
print "ce data1:"
print (ce_data_format)
ce_data_format = ""
for i in range(len):
ce_data_format+=data2[i]
if i < len-2:
ce_data_format+=','
print "ce data2:"
print (ce_data_format)
search_pattern = ""
search_data = ""
for i in range(len):
if data1[i] == data2[i]:
search_data+="\\x"+data1[i]
search_pattern+= "x"
else:
search_data+="\\x"+data1[i]
search_pattern+= "?"
print "search data:"
print search_data
print "search pattern"
print search_pattern
可以简单的看到相似的内容在哪里,哪些是变动的值
- x是相同值,?是 不同值
- ce data是用来给ce搜索验证目标串唯一 的
CE Kernel
好多教程都没说明,他们的CE是否有特殊处理或者加载某些额外的插件或者工具,来提升软件的权限或者躲避保护。
我以上说明都是基于原始CE来说的,但是需要额外开启CE Knernal,开启这个以后会造成部分游戏直接进不去,甚至触发游戏保护机制和反作弊系统。但是开了以后某些被简单保护的内存空间才能被搜索,否则搜都搜不到,还谈什么。
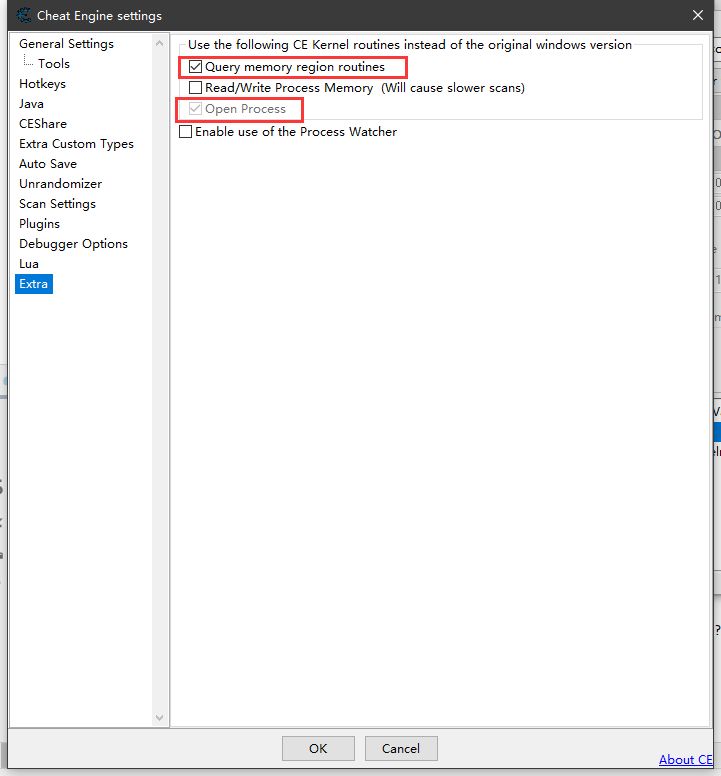
这个模式开启以后,关闭CE并不能解除模式,需要重启电脑,然后就正常了(特别是D2R)
Summary
作弊与反作弊,有太多的坑了,如果以后技巧还有提升,那在写一点,现在基本够我用了
Quote
https://www.52pojie.cn/forum.php?mod=viewthread&tid=915447
https://www.52pojie.cn/thread-1314107-1-1.html
https://www.bilibili.com/video/BV1Cf4y1p7bX?share_source=copy_web
https://www.bilibili.com/video/BV1c4411R794?share_source=copy_web