Foreword
总是能遇到一些奇葩问题,这里总结一下UDP常见丢包的原因以及一些特殊原因造成的UDP丢包。
UDP丢包
总的来说分成外因丢包和内因丢包,还有一些比较罕见,但是依然存在的特殊情况丢包也都记录在此
外部因素
带宽不够
这种比较常见,发包太多,或者网络环境不够好,最常见的丢包
UDP泛洪
这种是网络环境中存在某些特殊的存在,短时间大量发包,导致UDP触发防火墙的Flood防御,从而丢掉了某一路径上所有的UDP包
QoS
平常的QoS一般都是针对TCP的,但是保不齐也有某些针对UDP的QoS ,可能出于优化的目的,最终导致了部分UDP被丢包
内部因素
一般来说内部因素,完全看UDP的包送到应用的过程中,看看哪里会出问题,然后逐个检查即可。
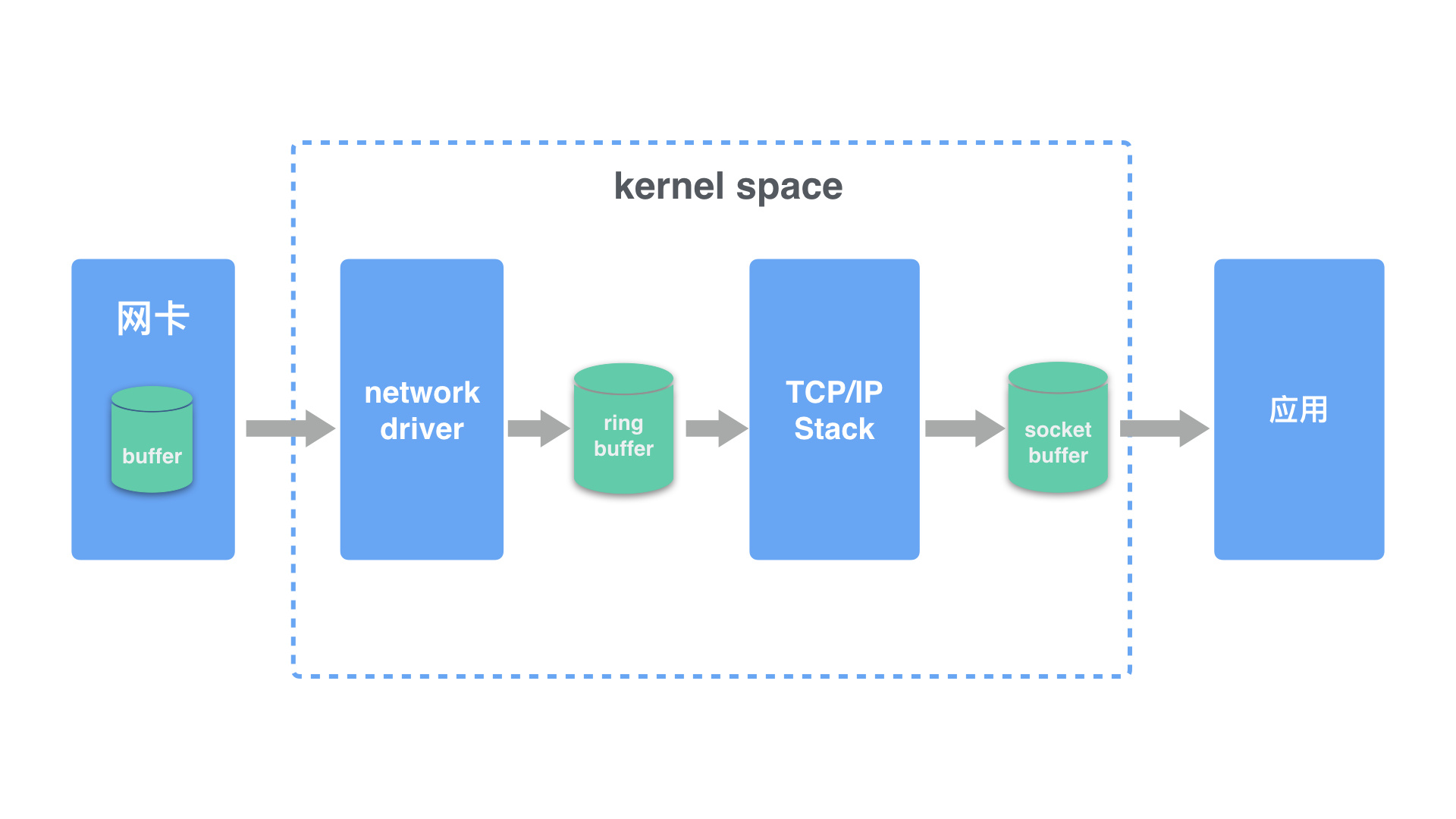
- 首先网络报文通过物理网线发送到网卡
- 网络驱动程序会把网络中的报文读出来放到 ring buffer 中,这个过程使用 DMA(Direct Memory Access),不需要 CPU 参与
- 内核从 ring buffer 中读取报文进行处理,执行 IP 和 TCP/UDP 层的逻辑,最后把报文放到应用程序的 socket buffer 中
- 应用程序从 socket buffer 中读取报文进行处理
硬件缓冲不足
首先是网卡本身的buffer,可以通过这个看具体的内容,查看是否有drop、bad相关的内容
ethtool -S eth0
ifconfig eth0
然后就是看ring buffer是否正常,同过下面的命令
ethtool -g eth0
修改则是通过如下方式
ethtool -G eth0 rx 8192
系统缓冲不足
linux内核socket缓冲区设的太小造成丢包,查看socket缓冲区的缺省值和最大值
cat /proc/sys/net/core/rmem_default
cat /proc/sys/net/core/rmem_max
还有一些其他可以算作缓冲的地方:
-
服务器负载过高,占用了大量cpu资源,无法及时处理linux内核socket缓冲区中的udp数据包,导致丢包。
-
磁盘IO忙,导致udp丢包。
-
物理内存不够用,出现swap交换,swap交换本质上也是一种磁盘IO忙,因为比较特殊,容易被忽视,所以单列出来。只要规划好物理内存的使用,并且合理设置系统参数,可以避免这个问题。
-
磁盘满导致无法IO,没有规划好磁盘的使用,监控不到位,导致磁盘被写满后服务器进程无法IO,处于阻塞状态。最根本的办法是规划好磁盘的使用,防止业务数据或日志文件把磁盘塞满,同时加强监控,例如开发一个通用的工具,当磁盘使用率达到80%时就持续告警,留出充足的反应时间
包过大
发送的包巨大丢包:虽然send方法会帮你做大包切割成小包发送的事情,但包太大也不行。例如超过50K的一个udp包,不切割直接通过send方法发送也会导致这个包丢失。这种情况需要切割成小包再逐个send
至于报文过大的问题,可以通过控制报文大小来解决,使得每个报文的长度小于MTU。以太网的MTU通常是1500 bytes,其他一些诸如拨号连接的网络MTU值为1280 bytes,如果使用speaking这样很难得到MTU的网络,那么最好将报文长度控制在1280 bytes以下。
包过大主要会造成UDP分片,而分片以后相当于丢包风险*N,只要其中一片丢了,那么最终这个UDP包无法完整拼接,就整个丢了。
频率过高
很多人会不理解发送速度过快为什么会产生丢包,原因就是UDP的SendTo不会造成线程阻塞,也就是说,UDP的SentTo不会像TCP中的SendTo那样,直到数据完全发送才会return回调用函数,它不保证当执行下一条语句时数据是否被发送。(SendTo方法是异步的)这样,如果要发送的数据过多或者过大,那么在缓冲区满的那个瞬间要发送的报文就很有可能被丢失。至于对“过快”的解释,作者这样说:“A few packets a second are not an issue; hundreds or thousands may be an issue.”(一秒钟几个数据包不算什么,但是一秒钟成百上千的数据包就不好办了)。 要解决接收方丢包的问题很简单,首先要保证程序执行后马上开始监听(如果数据包不确定什么时候发过来的话),其次,要在收到一个数据包后最短的时间内重新回到监听状态,其间要尽量避免复杂的操作(比较好的解决办法是使用多线程回调机制)
防火墙
防火墙就有多层了,要确认整个传输链路,每一层去确认防火墙到底是否有过滤或者丢包。
还需要确认系统防火墙是否有过滤对应的udp
程序提前终止
这种比较弱智,就是客户端发完了包,然后立马就断开了,此时服务端都还没处理完,连接就断了,导致后面包丢了
发现客户端连续发来1000个1024字节的包,服务器端出现了丢包现象. 纠其原因,是服务端在还未完全处理掉数据,客户端已经数据发送完毕且关闭了.
ARP缓存过期导致UDP丢包
ARP 的缓存时间约10分钟,APR 缓存列表没有对方的 MAC 地址或缓存过期的时候,会发送 ARP 请求获取 MAC 地址,在没有获取到 MAC 地址之前,用户发送出去的 UDP 数据包会被内核缓存到 arp_queue 这个队列中,默认最多缓存3个包,多余的 UDP 包会被丢弃。被丢弃的 UDP 包可以从 /proc/net/stat/arp_cache 的最后一列的 unresolved_discards 看到。当然我们可以通过
echo 30 > /proc/sys/net/ipv4/neigh/eth1/unres_qlen 来增大可以缓存的 UDP 包。
ARP过期会导致UDP丢包,这个是我没见过的
固定丢包
固定丢包的例子比较少见,也比较难搜索,下面的例子中就是交换机固定丢某一片UDP包,属于硬件bug,解包错误的了
https://blog.51cto.com/u_15333820/3464002
也有说是上级路由中加了过滤,符合某些特征的报文会被直接丢弃
https://blog.csdn.net/iteye_5014/article/details/81573955
偶发性成功,多数丢包
但是我遇见的比这个还要特殊,属于那种偶尔可以正常通信,多数时间是完全丢包的情况。
同时这个包的前包和后包,都对这个包不产生影响。
udp包的内容如下:
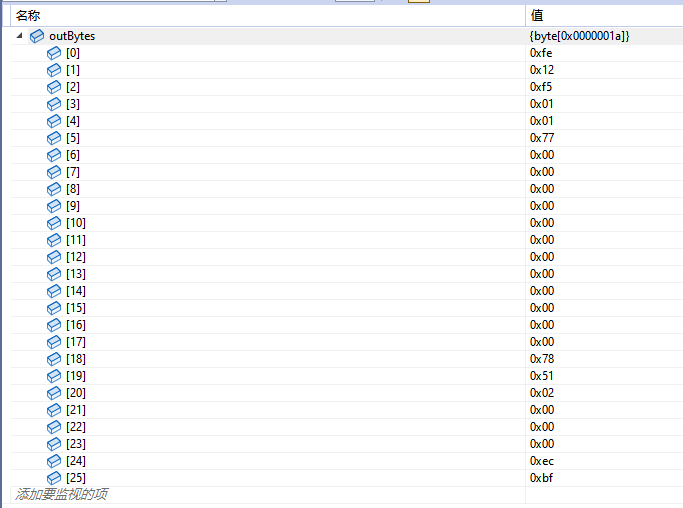
0xfe 0x12 0xf5 0x01 0x01 0x77 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x78 0x51 0x02 0x00 0x00 0x00 0xec 0xbf
这个序列可能头几次还能正常传输,后面就必定丢包。而修改了这个包的第5字节和最后2字节,依然会出现丢包的情况,所以怀疑是这个头被错误识别了。
- 这里0x**的地方是一个seq,每个包都会自动变
0xFE 0x12 0x** 0x01 0x01
之所以敢这么肯定,是因为当切换了路由器之后,这个问题直接就不存在了,这个包不会丢包了。
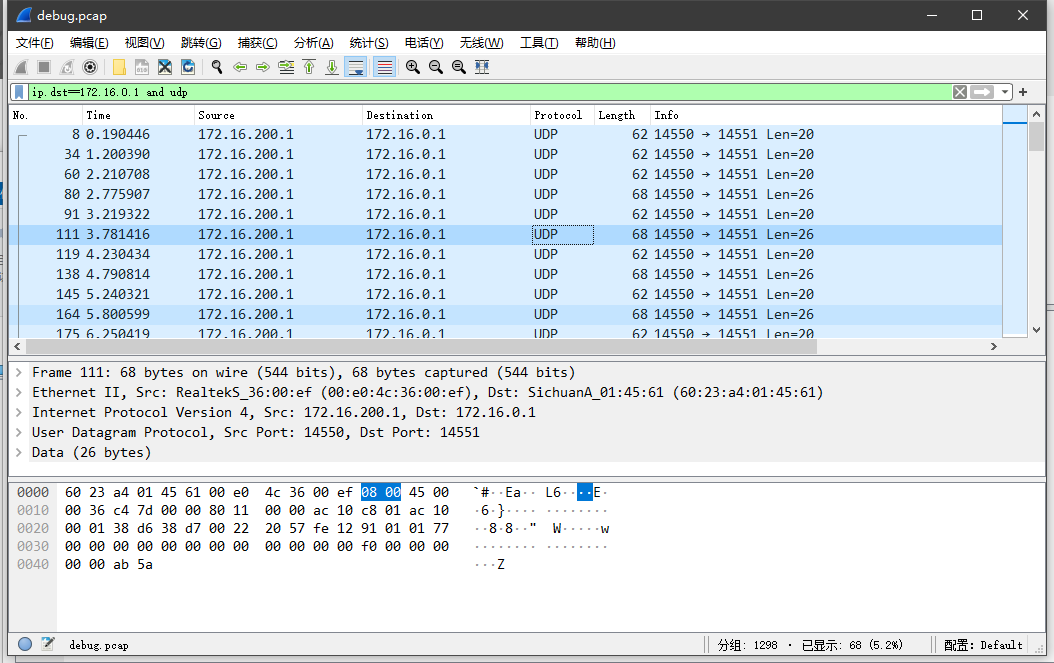
如果我在这个包之前加个字节或者包后加个字节,这个问题就直接不存在了,这个字节不限定是什么,只要加一个就不会被丢包了。
head:0x00 0xfe 0x12 0x** 0x01 0x01 0x77 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x78 0x51 0x02 0x00 0x00 0x00 0xec 0xbf
tail:0xfe 0x12 0x** 0x01 0x01 0x77 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x78 0x51 0x02 0x00 0x00 0x00 0xec 0xbf 0x00
这个问题反馈给了官方,官方回复是他们没有这个问题,他们用相同硬件和软件测试都是正常的,只能临时加个字节解决了
https://forum.mikrotik.com/viewtopic.php?t=185349
UDP粘包
理论上说UDP应该不会粘包,只有TCP可能会粘包。但是这一条在嵌入式的某些设备里可能会发生不同的情况。由于嵌入式设备本身内存小或者其他等原因,会导致发包的设备缓存包内容,并在后续的转发过程中将多个包合并发送,从而看起来像是UDP出现了粘包的问题。相同情况下,分包也是一样的,缓冲不够用,只好分几次发送,导致原本的一个包被分成了n个,但是这种情况只是自定义的数据帧被粘了或者分了,而UDP本身依然是独立,不受影响。
Summary
暂时遇到的就这么多,有了再更新
Quote
https://cizixs.com/2018/01/13/linux-udp-packet-drop-debug/?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
https://www.cnblogs.com/Zhaols/p/6105926.html
https://www.cnblogs.com/pandamohist/p/14139274.html
https://blog.51cto.com/u_15333820/3464002
https://blog.csdn.net/iteye_5014/article/details/81573955
https://www.iteye.com/blog/lbyzx123-2307530