Foreword
python解析mat文件,mat是matlab的数据集文件
mat文件解析
http://www.mathworks.com/help/pdf_doc/matlab/matfile_format.pdf
matlab的官方格式说明,但是这个文档很久没更新了,而且里面图片糊的要死
这里只针对mat v5的格式,目前最新的v7格式,发生的变化比较大,而且其本身也不能向下兼容
mat结构
文件头 固定128字节
数据元素块
- tag,根据tag决定元素块类型,大小
- data,具体内容
- 填充,保证数据对齐用的
Header
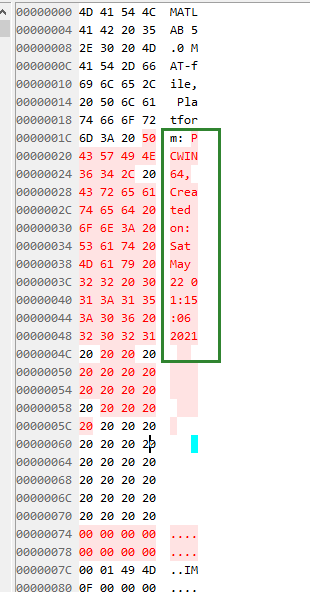
前128字节中会有一些mat的文件格式信息,比如是什么版本的mat文件和生成的平台。
这里面比较关键的就是最后的2字节,这里有一个IM或者MI的信息,用来表示当前文件是大端存储还是小端存储的,获取到这个以后就可以决定是否要交换数据的2个字节。
Data Block
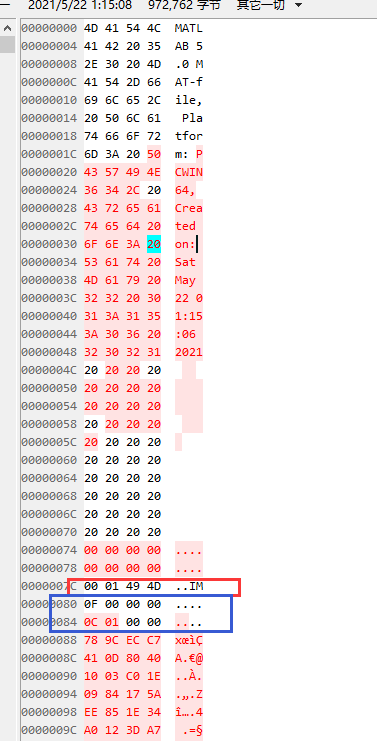
过了Header以后就是数据块了,默认的数据块前8字节是Tag

Tag里是有以下数据类型的标记,比如这里是0F,对应就是miCOMPRESSED压缩过的数据格式
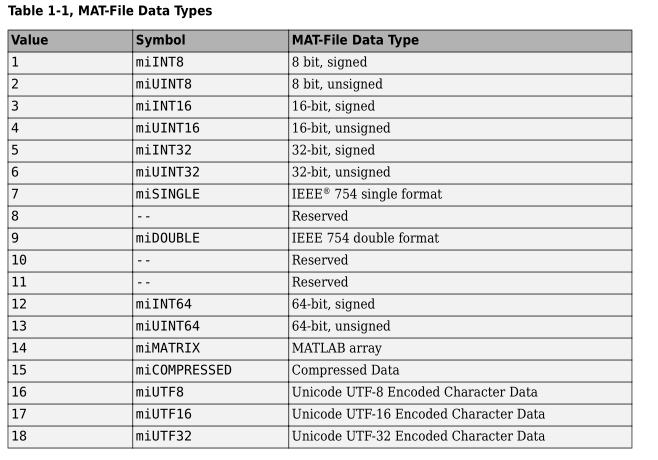
压缩的数据内容通过zlab即可解析,其他类型的数据就比较简单可以直接读出来解析。
小数据格式
也有一种特殊情况,这种是数据本身都是小字节占用,没必要使用8字节存储空间,于是整个Tag就不一样了。

这种Tag只有4字节,并且是先描述数据长度、再描述数据类型,后面跟随的就是数据本体了。
这种类型的格式可以通过Tag的前两个字节来判断,如果是普通数据格式前两字节必然为0(描述的是数据格式,高2字节都是0),如果是小数据格式,前两字节必然不为0(描述的是数据长度)
Padding
mat的数据部分也有padding的问题,一般来说正常格式就是8字节的padding对齐,如果是小数据格式,就是4字节对齐。
python解析mat
https://github.com/nephics/mat4py/tree/master
参考mat4py库,只是这个库有点问题
奇怪的问题
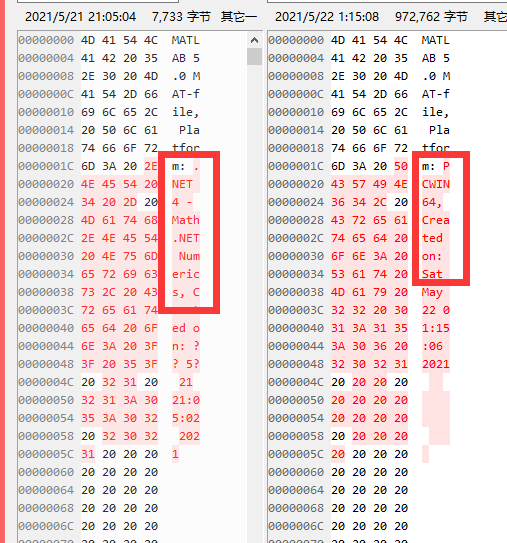
如果读取来自.NET 4生产的mat文件,并且数据格式是miCOMPRESSED的,就会出现zlib无法解析的问题,PCWIN64倒是可以正常解析
目前的解决办法是将获取到的数据块截断,去掉尾部1字节就能正常解析了
def read_var_header(fd, endian):
"""Read full header tag.
Return a dict with the parsed header, the file position of next tag,
a file like object for reading the uncompressed element data.
"""
mtpn, num_bytes = unpack(endian, 'II', fd.read(8))
next_pos = fd.tell() + num_bytes
if mtpn == etypes['miCOMPRESSED']['n']:
# read compressed data
data = fd.read(num_bytes)
dcor = zlib.decompressobj()
# from here, read of the decompressed data
// 去掉1字节
fd_var = BytesIO(dcor.decompress(data[:-1]))
del data
fd = fd_var
# Check the stream is not so broken as to leave cruft behind
if dcor.flush() != b'':
raise ParseError('Error in compressed data.')
# read full tag from the uncompressed data
mtpn, num_bytes = unpack(endian, 'II', fd.read(8))
if mtpn != etypes['miMATRIX']['n']:
raise ParseError('Expecting miMATRIX type number {}, '
'got {}'.format(etypes['miMATRIX']['n'], mtpn))
# read the header
header = read_header(fd, endian)
return header, next_pos, fd
Platform: .NET 4 - Math.NET这个文件应该是从.net的计算库而来

https://github.com/mathnet/mathnet-numerics/blob/master/src/Data.Matlab/Formatter.cs
mathdotnet是一个类似于matlab在net的计算库,里面封装了各种计算用的方法,并且支持部分matlab格式
https://www.mathdotnet.com/
https://github.com/mathnet
可以看到C# 最后塞了4字节的校验位
static byte[] PackCompressedBlock(byte[] data, DataType dataType)
{
var adler = BitConverter.GetBytes(Adler32.Compute(data));
using (var compressedStream = new MemoryStream())
{
compressedStream.WriteByte(0x58);
compressedStream.WriteByte(0x85);
using (var outputStream = new DeflateStream(compressedStream, CompressionMode.Compress, true))
{
outputStream.Write(BitConverter.GetBytes((int)dataType), 0, 4);
outputStream.Write(BitConverter.GetBytes(data.Length), 0, 4);
outputStream.Write(data, 0, data.Length);
outputStream.Flush();
}
compressedStream.WriteByte(adler[3]);
compressedStream.WriteByte(adler[2]);
compressedStream.WriteByte(adler[1]);
compressedStream.WriteByte(adler[0]);
return compressedStream.ToArray();
}
}
实际C#自己解析的时候,可以看到先是去掉了2个头部,也就是上面的0x58 0x85然后又去掉尾部的4字节,就是校验位
static byte[] UnpackCompressedBlock(byte[] compressed, out DataType type)
{
byte[] data;
using (var decompressed = new MemoryStream())
{
using (var compressedStream = new MemoryStream(compressed, 2, compressed.Length - 6))
using (var decompressor = new DeflateStream(compressedStream, CompressionMode.Decompress))
{
decompressor.CopyTo(decompressed);
}
decompressed.Position = 0;
var buf = new byte[4];
decompressed.Read(buf, 0, 4);
type = (DataType)BitConverter.ToInt32(buf, 0);
decompressed.Read(buf, 0, 4);
var size = BitConverter.ToInt32(buf, 0);
data = new byte[size];
decompressed.Read(data, 0, size);
}
return data;
}
然后就扔进去直接解析了,那这个写法就非常迷惑了,解析的时候完全不看校验位,只管解析。
实际上Platform: PCWIN64和Platform: .NET 4 - Math.NET在压缩的时候使用的数据头和尾不一样
0x78,0x9C win64 明文是 xœ
0x58 0x85 .net 明文是 X…
最后的校验位也是不计算头部的,只计算数据部分
比较奇怪的是zlib无论是否有后4字节都能正常解析PCWIN64,而.NET4的就不行了
这个标记具体的含义,估计要看zlib源码才能知道了
Summary
奇怪的问题
Quote
https://stackoverflow.com/questions/70262841/why-does-zlib-decompressobj-succeed-but-zlib-decompress-fail
https://www.loc.gov/preservation/digital/formats/fdd/fdd000440.shtml?__cf_chl_rt_tk=yNcjuWx04s8_z_4zHxnH2pt3q6G_Kl5TVcf0F1YMR_M-1695453961-0-gaNycGzNDWU#useful
http://www.mathworks.com/help/pdf_doc/matlab/matfile_format.pdf