Foreword
Blender中也有类似于maya goal的功能,叫做keyed,中文叫键控,非常奇怪的名字,打算看一下这个功能底层是怎么实现的,所以这里学习一下Blender的粒子架构。
Blender Dev
Blender本身内部功能都是用c开发的,音乐物理效果、游戏引擎和渲染是靠c++,插件和一些导入导出功能是python完成的。
blender的编译需要两个部分
一个部分是由svn来版本控制的预编译lib,在下图为pre-compiled libraries部分
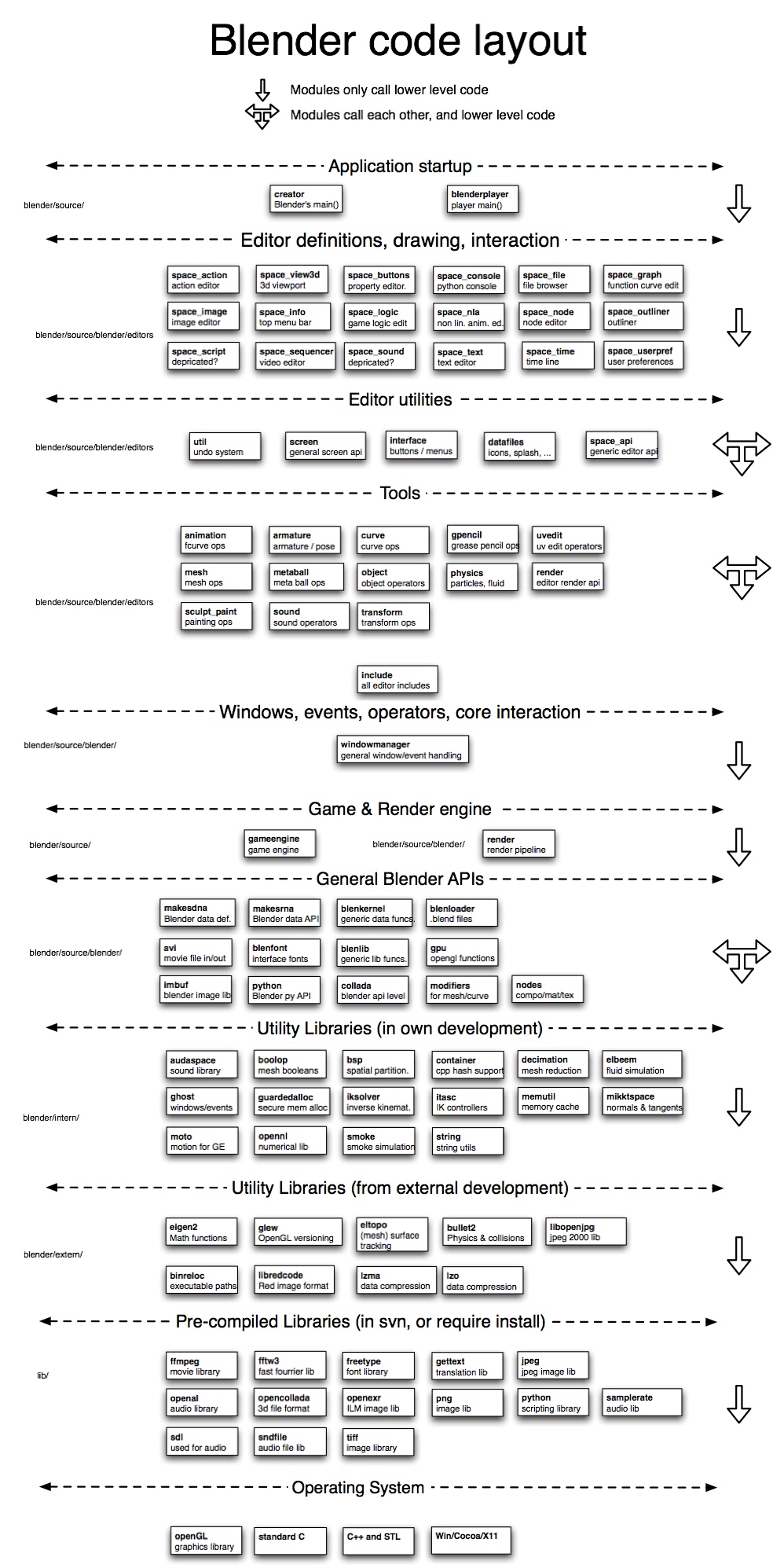
另外一个部分是由git来版本控制的源码,其中有三种,分为intern、extern和source三种,intern是blender开发的较为底层的一些源码,extern是非blender开发(如物理引擎bullet)的源码,source是较为上层的源码。这也能从图片左侧的路径看得出,source为blender/source路径,intern为blender/intern,extern为blender/extern。
缩写
一些常见的缩写,blender本身的wiki内容还是太少了,很多东西都搜不到,要不就是缩写
- GEN: General stuff (c++)
- SM: SuMo (Solid Uses Moto), the physics engine (c++)
- KX: Ketsji, the game engine (c++)
- MT: MaTh, mathematics module (c++)
- RE: Render, static rendering (c)
- PR: Portable Runtime, a Netscape library (external code, c)
- PRB: PR-Blender, our own extensions to PR (c)
- SND: SouND, our (currently OpenAL) wrapper and extensions (c)
- RAS: RASterizer, our low level 3D polygon abstraction layer (c++)
- NET: NETworking. Currently our Terraplay CNI wrapper.
- BLI: Blender low-level LIbrary.
- BKE: Blender KErnel.
- BIF: Blender Interface Framework.
- BSE: Blender Space Editor.
- BDR: Blender DRawing.
- DNA: struct DNA, the types definitions of serializable data, and the construction of DNA.o, which encodes this data.
- AVI: conversion of AVI format files.
- IMB: IMage Buffer, all kind of operations on images.
ID Datablocks
简单说由于代码是C写的,所以所有数据结构都是struct,并且规定了一些通用类型命名查询的方式和数据结构的排布
typedef struct Mesh {
ID id;
struct AnimData *adt;
…
};
命名规则:
UI中显示为Suzanne的mesh类型,实际在数据块中命名时MESuzanne
由于是C,所以没有面向对象,这里要用通过名称获取对应的数据类型的时候,就是通过,字符串来反射实际的数据类型
if (GS(id->name) == ID_SC)
ID Types
和maya一样,每个类型有一个独一无二的id,而maya规定死了,必须要向maya官方注册你的id,然后才能保证和别的插件一起用的时候不会出现节点id冲突的问题,blender也是一样的,需要这样的结构,不过blender可以动态注册到系统中
IDTypeInfo IDType_ID_OB = {
.id_code = ID_OB,
.id_filter = FILTER_ID_OB,
.main_listbase_index = INDEX_ID_OB,
.struct_size = sizeof(Object),
.name = "Object",
.name_plural = "objects",
.translation_context = BLT_I18NCONTEXT_ID_OBJECT,
.flags = 0,
.init_data = object_init_data,
.copy_data = object_copy_data,
.free_data = object_free_data,
.make_local = object_make_local,
};
添加一个新类型
- 在相关的文件中定义一个IDTypeInfo,比如 mesh.c 与 ID_ME
- 在BKE_idtype.h中添加新类型的extern 声明
- 在idtype.c中的id_type_init()函数注册新类型
RNA & DNA
Blender中的RNA和DNA就是生物中的RNA和DNA的含义(不得不吐槽,非常容易让人费解,我还以为什么是什么Data xxx access)。
Blender中各种基础数据类可以说就是DNA(不同版本的DNA自然就不同了,对应显示出来的Blender这个个体就不一样了)
RNA则是对各种数据类进行二次操作或者翻译,RNA主要将DNA中的数据解释给用户或者是直接给到Blender内部使用。我是看的一脸懵逼,后面看明白了再说吧。
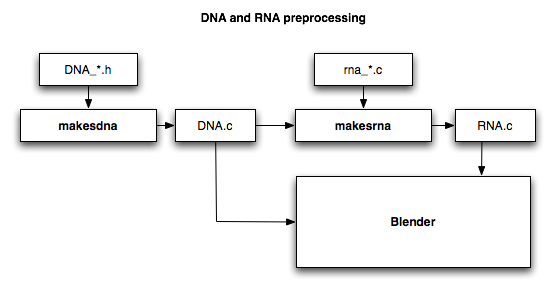
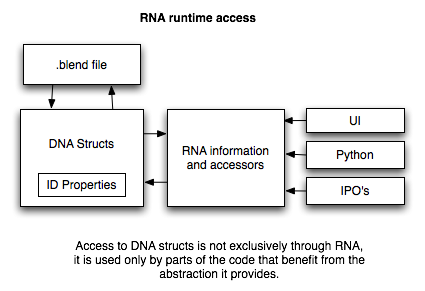
粒子系统架构
粒子系统本质上是一个模拟系统,而模拟系统的有一个核心思想,那就是依赖于前一刻的状态,模拟下一刻的状态。如果没有前一刻的状态,那么下一刻的状态是不可知的。
模拟粒子系统中有中心化和分布式的模拟两种大类,但是分布式需要非常快快速的模拟器,性能要求也更高,基本做不到,所以只能妥协选择中心式的模拟器
总体架构
void simulate_step(ParticlesState &, StepDescription &)
简单说,这就是一个粒子模拟器,一般来说是实时的,每次运行都会输入当前的粒子状态和解算器
ParticlesState
StepDescription
ParticlesState,只用来存储粒子的所有数据
StepDescription,用来描述上一帧的粒子是如何变化到下一帧的,其实就是具体的解算器
这样一个粒子模拟系统就ok了,不过这样的话模拟必须是离散的,必须是 one step by one step
粒子存储
数据存储的方式会影响到计算时百万级别的粒子的计算性能,所以非常重要。
- 使用动态内存管理,相对应的静态内存可能更快一些,但是无法适应于内存大小不一致的各种pc
- 使用属性数组,相对应的是对象数组,使用对象数组的好处是他面向对象,增减属性的时候非常方便,管理起来也容易,但是带来的就是性能下降。而粒子这里,经常需要修改相同属性,比如位移,速度,如果是属性数组,内存连续,修改起来非常快。同时粒子里多数情况都是对整体的修改,也就是所有粒子个体都需要更新,而不是只更新个别几个,所以最后选择了属性数组
存储的结构
简单说就是粒子状态包含粒子容器,粒子容器中使用粒子块,粒子块中才包含具体的属性数组,每个粒子块在同一个容器中大小是相同的。
- Particles State
- Particle Containers
- Particle Blocks
- attribute arrays of particles
- Particle Blocks
- Particle Containers
属性
属性和粒子容器都是通过名称识别的
结算器
StepDescription 中包含了粒子发射器和粒子类型,这里粒子类型比较复杂,它包含了粒子的属性、事件、积分器、还有一些偏移控制。换而言之,一个粒子对象,他的funcs和具体的data是分离的,同一个data甚至可能可以给其他粒子去用。StepDescription中则是包含了对这个粒子的描述funcs。
发射器
主要是创建和初始化粒子,还有一些粒子生命周期的统计信息
积分器
积分,其实就是迭代,描述粒子属性如何变化
事件
事件中包含两个东西,一个是过滤器,一个是执行器。说白了前者是条件,后者是对应的操作。
偏移控制
这个没看懂,说是可以修改属性和创建粒子,但是他的原理或者原则是什么。感觉应该是用来调试或者一些附加在粒子上的操作,比如粒子需要轨迹的时候,通过偏移控制来绘制粒子轨迹之类的
模拟器
模拟器首先检查是否需要的粒子都有了,属性也存在,然后发射器发射粒子或者模拟粒子,最后将结果压缩存储。
单粒子模拟流程:
积分器中时间前进一个单位,然后计算出来粒子需要改变的量是什么,检查是否会触发一些事件,如果触发了依次执行对应的执行器,他们可能会修改粒子属性,目前最多是能被10个事件触发修改,粒子生命减少,一直循环,最后粒子被标记死亡,然后被移除
粒子发射,发射的时候是多线程发射的,但是由于访问内存需要加锁,当有一个线程发送的时候,他会申请一个新的粒子块,然后将发射的粒子属性填充到这个粒子块中。这里一次发射会把块填满才会解锁内存占用。
压缩是将粒子数据重新排列组合填充满粒子块,而多余的块会被释放或者当作缓存回收了。
Summary
见了鬼,keyed的时候粒子不支持自碰撞,那keyed的功能就非常简单了,直接从原点移动到目标点就结束了,复杂一点就是中间加一个路径,然后按照路径移动而已,但是这过程中粒子是会重叠的,这就和我预期有区别了。
Quote
https://wiki.blender.org/wiki/Source/Nodes/ParticleSystemCodeArchitecture
https://wiki.blender.org/wiki/Source/Nodes/SimulationArchitectureProposal
https://wiki.blender.org/wiki/Source/Architecture/ID
https://zhuanlan.zhihu.com/p/97210861
https://zhuanlan.zhihu.com/p/157316153