Foreword
有些关于Tracealyzer介绍的地方可能也没说清楚,这里再补充一些
以及有可能遇到的一些问题也都补充在这里
环境
- Tracealyzer4.3.5版本
- FreeRTOS 9.0
- STM32F767
- Windows
内存不够
由于之前的经验,我们这个bug要比较长时间才能出现,30分钟左右,我就想记录30分钟左右的数据,然后每次都被Tracealyzer卡死。
然后仔细对比了一下,Tracealyzer大概记录2分钟左右的数据,内存消耗就两个多g,如果30分钟,大概要60多g,我32g根本不够用,数据大概只有300多M,但是加载的时候会直接卡住。没办法只能一点一点记录,当然这个和系统环境也有关系,我们数据量算是比较大的,如果数据量小可能记录的久也没啥问题。
这个不绝对,在Tracealyzer的任务数比较少,记录项比较少的情况下,记录400多M,44分钟也没问题了。
关闭可视化
建议在streaming模式下关闭可视化,主要是streaming模式下数据量大,可视化很卡,而且这个时候讲道理你也看不清啥,等数据记录完了以后再可视化
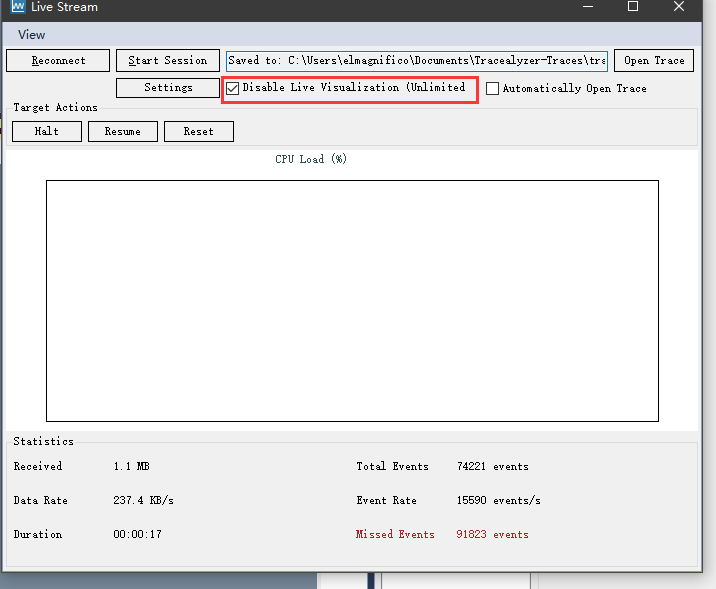
还有一点有时候开着可视化会莫名其妙的丢包,导致missed events突然就跳了
同步
界面中的同步就是指各个数据窗口是否同步时间轴,你拖动了一个,其他的也相应移动到对应位置上
Actor
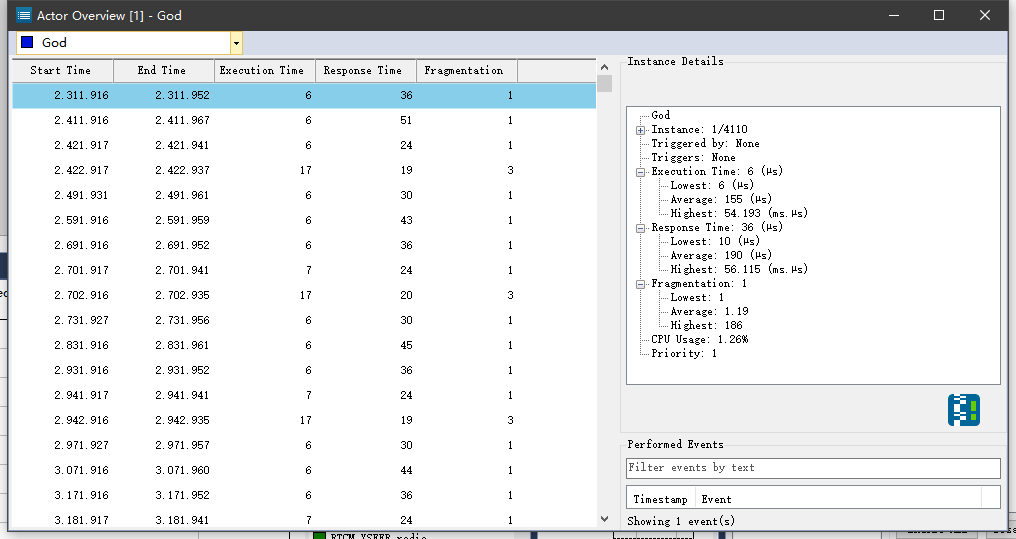
在Actor Overview中可以看到各个线程的调用情况。
- Execution Time 是指实际的执行时间
- Response Time 是指任务进入就绪状态到执行结束的耗时
- Fragmentation 是指被切换或者调度的次数,正常没有被切换就是1,如果被高级线程中断了那就+1
- Wait Time 是指就绪态到执行态等待的时间
但是以上数据都是基于当前这个通道来说的,如果还有任务不在这个通道,并且打断了这个task其实是不会记录进来的,所以这里的数据都是相对的。
TzCtrl
可能会看到一个线程叫TzCtrl,这个是trace的线程忽略就行了。
他主要用来记录数据,过滤数据,发送数据什么的。
miss event
先说流模式中有两种传输方式,一种是阻塞式一种是非阻塞式,阻塞式的会严重影响到系统运行,但是不会丢包,如果系统空闲时间比较多的话,可以用,但是对于系统复杂度比较高,阻塞式可能问题就比较大了,会导致系统明显运行速度慢了很多。非阻塞式的好处就是,尽可能传数据,但是不能保证不丢包,丢了的话就会导致你看到的任务执行时间或者等待时间出现异常,跳跃非常大的一个时间段。
如果系统比较小,可能不会有miss event发生,或者数量非常小,基本可以忽略。
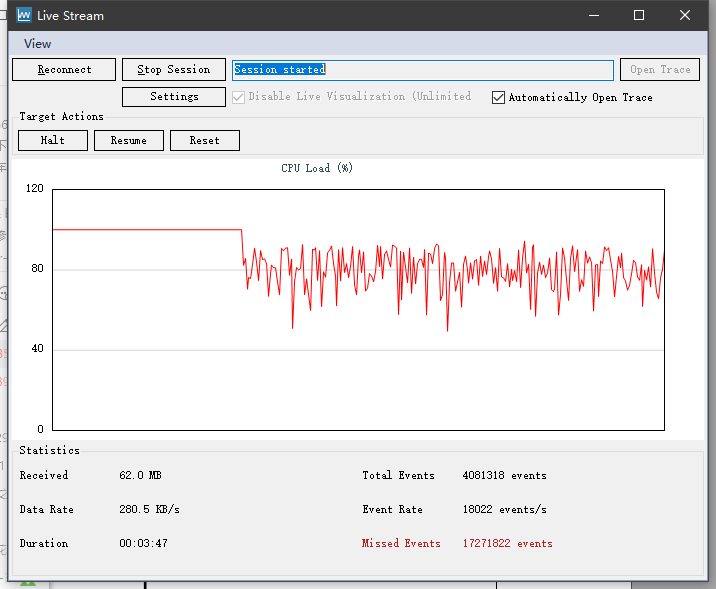
根据当前数据计算所需要的数据速率有多少
(Total Events+Missed Events) * (Received/Event Rate) / Duration
这样就能计算出来你当前系统实际需要的数据速率大概是多少,上图中的例子,需要的速率大概是1463KB/s,而tracealyzer的默认配置能提供的速率大概是280KB/s,已经远超了,从图里也能看到当前速率其实已经翻倍了。
解决办法
- 首先检测是否jink固件是新版的,jlink的线是否连接ok,简单说确保硬件稳定,并且固件是最新版的,这个会影响到传输效果,jink的时钟速率是否足够,过小会引起数据速率很低
- 修改内部配置,增大数据存储栈,增加传输率
- 减少数据传输量,对不需要的数据进行过滤,减少丢包。
目前只有这三种办法来缓解missed events
配置优化
trcConfig.h中,这两个关闭可以减少大概一半的流量吧
是否记录就绪事件
TRC_CFG_INCLUDE_READY_EVENTS
是否记录系统时钟事件
TRC_CFG_INCLUDE_OSTICK_EVENTS
还有类似的配置,比如关闭记录中断,关闭记录用户通道等等。
自定义记录通道
使用这两个来自定义用户通道
vTraceSetFilterMask
vTraceSetFilterGroup
这里说一下我遇到的问题,我系统中有几个任务的执行频率基本都是1000hz的,高频任务比较多,所以数据量就非常大。官方给的几个办法,增大buff,提高传输任务优先级,提高传输任务频率等等,最后都无法传输这么大数据量,所以只能使用自定义通道过滤不需要的事件,从而减少数据量。
trcConfig.h中的配置是相当于一个全局性的开关,都是针对系统层级的某些东西是否记录。而要具体到是否记录这个任务的相关事件,则是要用自定义用户通道来完成。
系统里一共给了16个自定义通道,其实就是16个集合,可以自己分类各个任务到各个通道,默认所有任务都是自动分配到通道0的
#define FilterGroup0 (uint16_t)0x0001
#define FilterGroup1 (uint16_t)0x0002
#define FilterGroup2 (uint16_t)0x0004
#define FilterGroup3 (uint16_t)0x0008
#define FilterGroup4 (uint16_t)0x0010
#define FilterGroup5 (uint16_t)0x0020
#define FilterGroup6 (uint16_t)0x0040
#define FilterGroup7 (uint16_t)0x0080
#define FilterGroup8 (uint16_t)0x0100
#define FilterGroup9 (uint16_t)0x0200
#define FilterGroup10 (uint16_t)0x0400
#define FilterGroup11 (uint16_t)0x0800
#define FilterGroup12 (uint16_t)0x1000
#define FilterGroup13 (uint16_t)0x2000
#define FilterGroup14 (uint16_t)0x4000
#define FilterGroup15 (uint16_t)0x8000
vTraceSetFilterGroup(FilterGroup0);
vTraceSetFilterGroup的含义就是开启一个划分,这句往下到另外一个划分为止,这之间所有开启的任务都属于一个通道。
// 由于未指定通道,默认都归属于通道0
xTaskCreate( vTaskFunction1, "TASK1", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
xTaskCreate( vTaskFunction1, "TASK2", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
//指定通道0,所以他们也归属于通道0
vTraceSetFilterGroup(FilterGroup0);
xTaskCreate( vTaskFunction1, "TASK3", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
xTaskCreate( vTaskFunction1, "TASK4", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
//指定通道1,所以任务5、6都是通道1的
vTraceSetFilterGroup(FilterGroup1);
xTaskCreate( vTaskFunction1, "TASK5", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
xTaskCreate( vTaskFunction1, "TASK6", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
//指定通道2,所以任务7、8都是通道2的
vTraceSetFilterGroup(FilterGroup2);
xTaskCreate( vTaskFunction1, "TASK7", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
xTaskCreate( vTaskFunction1, "TASK8", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
//指定通道0,所以他们也归属于通道0
vTraceSetFilterGroup(FilterGroup0);
xTaskCreate( vTaskFunction1, "TASK9", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
xTaskCreate( vTaskFunction1, "TASK10", TASK_STACK_SIZE, NULL, TASK1_PRIORITY, NULL );
划分好了通道以后,还需要设置一下具体这次输出到底输出什么通道,这就靠vTraceSetFilterMask
vTraceSetFilterMask( FilterGroup1 | FilterGroup2 );
这样就设定了,只输出通道1和通道2的任务信息,而通道0的信息是完全不会输出的。
通过这样的方式我就把原来1400多KB/s的总数据流分割成若干个小数据流,然后每次烧写修改具体要查看的数据流到底是哪个。
动态分组
上面说了分组来实现流量切割,实际上测试了一下也可以动态分组,分组用的是一个全局变量,只要前面的步骤正确,那么可以直接切换实际输出的通道。
switch(params[0]){
case 0:
vTraceSetFilterMask(FilterGroup0);
break;
case 1:
vTraceSetFilterMask(FilterGroup1);
break;
case 2:
vTraceSetFilterMask(FilterGroup2);
break;
case 3:
vTraceSetFilterMask(FilterGroup3);
break;
case 4:
vTraceSetFilterMask(FilterGroup4);
break;
case 5:
vTraceSetFilterMask(FilterGroup5);
break;
case 6:
vTraceSetFilterMask(FilterGroup6);
break;
default:
printf("unknow FilterMask \n");
return;
}
printf("tracealyzer set FilterMask ok\n");
CPU 100%
Tracealyzer的cpu计算方式挺奇怪的,他计算的是这个负载量,而不是真的整个系统的cpu负载。
也就是说你通道里只有部分任务,所有任务都在跑的情况下,那么cpu就是100%.如果你加上一个不频繁跑的任务进去cpu可能就变成90%了
所以这里cpu统计的是相对量,是指输出通道中的所有任务是100%,占比也是基于这个,而不是实际cpu的使用100%
End
目前遇到Tracealyzer中的坑大概就这么多,日后有了再补充吧
Quote
http://www.cirmall.com/bbs/forum.php?mod=viewthread&tid=160179
https://percepio.com/2018/10/11/tuning-your-custom-trace-streaming/
https://percepio.com/docs/FreeRTOS/manual/#Creating_and_Loading_Traces__Percepio_Trace_Recorder__FreeRTOS_jlink-troubleshooting